Applications Of Machine Learning To The Problem Of ... - PubMed
Maybe your like
Abstract
Antimicrobial resistance (AMR) remains one of the most challenging phenomena of modern medicine. Machine learning (ML) is a subfield of artificial intelligence that focuses on the development of algorithms that learn how to accurately predict outcome variables using large sets of predictor variables that are typically not hand selected and are minimally curated. Models are parameterized using a training data set and then applied to a test data set on which predictive performance is evaluated. The application of ML algorithms to the problem of AMR has garnered increasing interest in the past 5 years due to the exponential growth of experimental and clinical data, heavy investment in computational capacity, improvements in algorithm performance, and increasing urgency for innovative approaches to reducing the burden of disease. Here, we review the current state of research at the intersection of ML and AMR with an emphasis on three domains of work. The first is the prediction of AMR using genomic data. The second is the use of ML to gain insight into the cellular functions disrupted by antibiotics, which forms the basis for understanding mechanisms of action and developing novel anti-infectives. The third focuses on the application of ML for antimicrobial stewardship using data extracted from the electronic health record. Although the use of ML for understanding, diagnosing, treating, and preventing AMR is still in its infancy, the continued growth of data and interest ensures it will become an important tool for future translational research programs.
Keywords: antibiotic resistance; antimicrobial stewardship; drug discovery; machine learning; mechanisms of action; whole-genome sequencing.
PubMed Disclaimer
Figures
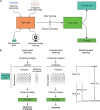
FIG 1
General overview of machine learning…
FIG 1
General overview of machine learning analyses. (A) ML analyses are capable of integrating…

FIG 2
Schematic overview of the process…
FIG 2
Schematic overview of the process of training a machine learning (ML) model to…
References
-
- Centers for Disease Control and Prevention. 2019. Antibiotic resistance threats in the United States, 2019. Centers for Disease Control and Prevention, Atlanta, GA.
-
- O’Neill J. 2016. Tackling drug-resistant infections globally: final report and recommendations. Analysis and Policy Observatory, Hawthorn, Australia. https://amr-review.org/sites/default/files/160518_Final%20paper_with%20c....
-
- Burkov A. 2019. The hundred-page machine learning book. Andriy Burkov.
-
- Bzdok D, Altman N, Krzywinski M. 2018. Statistics versus machine learning. Nat Methods 15:233–234. 10.1038/nmeth.4642. - DOI - PMC - PubMed
-
- Schuler MS, Rose S. 2017. Targeted maximum likelihood estimation for causal inference in observational studies. Am J Epidemiol 185:65–73. 10.1093/aje/kww165. - DOI - PubMed
Publication types
- Review Actions
- Search in PubMed
- Search in MeSH
- Add to Search
MeSH terms
- Anti-Bacterial Agents* / pharmacology Actions
- Search in PubMed
- Search in MeSH
- Add to Search
- Anti-Infective Agents* / pharmacology Actions
- Search in PubMed
- Search in MeSH
- Add to Search
- Artificial Intelligence Actions
- Search in PubMed
- Search in MeSH
- Add to Search
- Drug Resistance, Bacterial Actions
- Search in PubMed
- Search in MeSH
- Add to Search
- Humans Actions
- Search in PubMed
- Search in MeSH
- Add to Search
- Machine Learning Actions
- Search in PubMed
- Search in MeSH
- Add to Search
- Translational Research, Biomedical Actions
- Search in PubMed
- Search in MeSH
- Add to Search
Substances
- Anti-Bacterial Agents Actions
- Search in PubMed
- Search in MeSH
- Add to Search
- Anti-Infective Agents Actions
- Search in PubMed
- Search in MeSH
- Add to Search
Grants and funding
- R00 GM118907/GM/NIGMS NIH HHS/United States
- R01 AI146194/AI/NIAID NIH HHS/United States
LinkOut - more resources
Full Text Sources
- Atypon
- Europe PubMed Central
- PubMed Central
Other Literature Sources
- The Lens - Patent Citations Database
- scite Smart Citations
Medical
- ClinicalTrials.gov
- MedlinePlus Health Information
Miscellaneous
- NCI CPTAC Assay Portal
Tag » A Review Of Artificial Intelligence Applications For Antimicrobial Resistance
-
A Review Of Artificial Intelligence Applications For Antimicrobial ...
-
(PDF) A Review Of Artificial Intelligence Applications For Antimicrobial ...
-
A Review Of Artificial Intelligence Applications For Antimicrobial ...
-
[PDF] Application Of Artificial Intelligence In Combating High ... - MDPI
-
Application Of Artificial Intelligence In Combating High Antimicrobial ...
-
Antimicrobial Resistance With Artificial Intelligence | IDR
-
A New Hope In The Fight Against Antimicrobial Resistance ... - NCBI
-
Accelerating Antibiotic Discovery Through Artificial Intelligence - Nature
-
Applications Of Machine Learning To The Problem Of ... - ASM Journals
-
Antibiotic Resistance: How AI Can Tackle The Superbug Threat
-
A Review Of Artificial Intelligence Applications For Antimicrobial ...
-
Prediction Of Antimicrobial Resistance Based On Whole-genome ...
-
Development Of Artificial Intelligence For Applications In Pathogen ...
-
Using AI To Detect Antibiotic Resistance - News-Medical