How To Remove Negative Information From The Internet?
Maybe your like
 Sameer Somal May 4, 2025 | 1 min read Updated February 27, 2026 #Blog, #Digital Transformation, #Online Reputation Management, #Remove Negative Reviews, #SEO Tips
Sameer Somal May 4, 2025 | 1 min read Updated February 27, 2026 #Blog, #Digital Transformation, #Online Reputation Management, #Remove Negative Reviews, #SEO Tips  Table of Contents
Table of Contents Removing Content From Google Search
Why Do Negative Articles Rank So Highly on Google?
How To Remove Negative Information From the Internet?
Conclusion
Frequently Asked Questions
Building and maintaining a brand’s reputation takes a lifetime, and all your hard work can be jeopardized if a negative article or review about your company is the first result that pops up in a Google search. Negative information refers to any online content—such as critical reviews, unfavorable news stories, negative social media posts, or damaging comments—that undermines trust, credibility, or esteem in the eyes of your audience.
Brands have tried to manage their images since the advent of media, but the Internet and the dominance of one search engine have made maintaining public opinion and a stable online presence incredibly challenging. To be clear, removing personal online content or reviews from Google entirely is not possible. Instead, your goal should be to address and mitigate the damage such items cause. That can be done through the strategies of online reputation management.
A 2025 survey by ReviewTrackers found that 94 percent of consumers say they will avoid a business because of a negative review. This underscores why reputation management must be proactive and ongoing.
This article will explain why Google surfaces negative information in its results and why the best tactic is not removal but displacement—burying damaging content by promoting new, positive content in search engine rankings.
Related –
How to Remove a Negative Google Review: 3 Ways That Actually Work
Read More
Why Negative Content Still Ranks High?
Below are the core forces that let negative articles dominate search results, along with new twists not fully explored in your original summary.
1. Google’s intent-sensitive signals (QDD, QDF, and more)
Query Deserves Freshness (QDF)
Google still uses the notion of “freshness” to prefer more recent content when a topic is trending or evolving. If your brand is suddenly in the news for a scandal, that negative content is “fresh,” and Google will often prioritize it.
Query Deserves Diversity (QDD) + related signals
Google also seeks viewpoint diversity. If there’s not much countercontent (positive or neutral), the negative perspective can dominate by default.
Over time, Google’s algorithms have grown more nuanced. They now look at user signals (clicks, dwell time, pogo-sticking) and “engagement quality” to decide which versions deserve visibility.
2. Clicks, presentation bias, and “attractiveness” of negative headlines
Click probability & predictive models
Google increasingly uses predictive models to estimate which search results users are likely to click, based on historical behavior. Higher click probability gives a ranking boost. Negative or sensational titles often generate more clicks, giving them an algorithmic edge.
Presentation bias
Even beyond position bias (rank-1 gets more attention), users are biased toward results with more compelling or alarming titles. Experiments show “attractiveness” (how enticing a snippet looks) can inflate click rates.
Furthermore, outlier results, ones that starkly differ from others in tone or presentation, tend to draw disproportionate attention.
3. Network reinforcement and content “topic density”
Once a negative article appears on a reputable site, it tends to get syndicated, referenced, and echoed by others. The more it is repeated, the stronger the web of interlinked evidence becomes, which signals to search engines that it’s a legitimate, widely recognized fact.
Your original point about “someone trusted writes it, others amplify” still holds. But nowadays, algorithms view the density of related mentions, entity associations, and cross-linking as signs of authority.
4. Brand authority, E-E-A-T, and “familiar names” bias
Google places a heavy weight on expertise, experience, authority, and trustworthiness (E-E-A-T). Well-known media outlets already have domain authority, so when they publish negative content, it gets more weight.
Also, algorithms appear to favor “known names” in their AI summaries and overviews (where Google tries to give an answer box). Smaller or newer sources may struggle to break in.
That means negative content from an established outlet may outrank a superior counterargument published on a lesser-known site.
5. Google’s answer/summary features
Lately, Google has been more aggressive about using AI Overviews (aka “answer boxes” or summary panels) above traditional organic results. Those often reference major, established outlets.
If Google’s summary leans toward the negative article (because of brand weight or high clicks), it can further drown out your own content, making the negative version more visible by default.
6. Accuracy is not a direct ranking signal
Google does not explicitly detect factual accuracy or truth. Instead, it uses proxies like user engagement, domain authority, E-E-A-T signals, internal signals, and external signals.
Thus, well-crafted but false or misleading negative content can still outrank truthful, well-researched rebuttals if it minimizes bounce rates, gets clicks, accumulates endorsements, and is from a strong domain.

Is Removing Negative Info from the Internet Possible? How?
Removing or suppressing negative content is challenging but not impossible. In many cases, unpublishing or legal takedown requests (for defamation, copyright violation, or privacy breach) may succeed. More often, companies combat negative content by publishing high-quality, positive content to push the negative items down in search. The best defense is proactive reputation management long before a crisis erupts.
According to BrightLocal’s 2025 survey, just 42 % of consumers trust reviews as much as personal recommendations, down from 79 % in 2020.
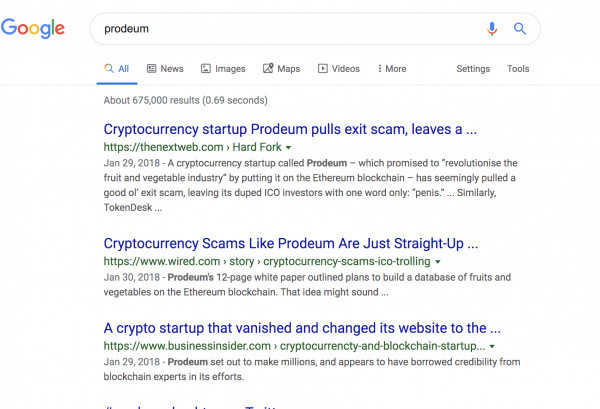
Image Credits: Blue Ocean Global Technology
How to remove negative information from the internet? 3 Major Steps
In the digital age, a single negative story can shape public perception and damage a brand’s credibility overnight. Managing online reputation has therefore become as vital as delivering a quality product or service. While public relations can shift opinion, sustainable recovery begins with a clear understanding of the problem, strategic content removal, and consistent creation of positive visibility. The following three-step guide reflects the most recent 2025 developments in Google content removal and reputation management, supported by current data and research. It offers a practical framework for restoring trust, controlling search results, and strengthening your online presence.
1. Define clearly what’s wrong and why it matters
- Begin with a root-cause analysis. Was the negative content caused by a mistake, malicious action, or misunderstanding?
- Determine the damage vector: is it harming search results, social reputation, business leads, legal exposure, etc.?
- Set measurable goals: “reduce negative mentions on page one,” “restore trust among customers,” or “deter future incidents.”
2. Remove or neutralize harmful content (where feasible)
- Use Google’s Outdated Content Removal tool or the “Remove personal information” request to de-index content you no longer control.
- If content is defamatory, factually wrong, or breaches platform policy, file takedown requests with site owners, Google, or social media platforms.
- In jurisdictions that recognize “right to be forgotten,” submit formal removal requests, balancing privacy rights against public interest.
Note: Even when content is removed, it may linger in residual caches or be resurfaced elsewhere.
3. Bury the negatives with stronger, positive content
- Create and promote high-quality, authoritative content (articles, press releases, thought leadership) on domains you control (your website, LinkedIn, Medium). This is “reputation SEO“.
- Use SEO and link building to ensure your positive content outranks the negatives. Strong pages push negative ones downward.
- With paid ads (e.g. Google Ads), bid on key terms tied to your brand so your pages appear above organic negative results.
- Maintain a proactive PR and content schedule to keep new, favorable content flowing. Over time, newer content naturally displaces older negatives.
Below is a summary of the most effective methods to remove or manage negative information on the internet. Each option varies in difficulty, speed, and long-term impact. Understanding these choices helps you decide the best course of action for restoring and protecting your online reputation.
| Approach | Description | Effectiveness | Best For |
| Direct Publisher Contact | Request removal or correction from the site owner. | Moderate | Personal posts, blogs, or small sites. |
| Google Tools for Removal | De-index outdated or private information through Google’s forms. | High (for policy -violating content) | Search results tied to personal data. |
| Legal Action | Pursue takedown under defamation, copyright, or privacy law. | Variable, often slow | False or harmful claims. |
| Reputation SEO | Publish authoritative, optimized content to outrank negatives. | High over time | Brand or professional reputation repair. |
| Paid Advertising | Use pay-per-click ads to place positive results above organic listings. | Immediate but temporary | Short-term visibility boost. |
| Professional Services | Hire a reputation management agency for content suppression and PR. | High (cost varies) | Complex or large-scale damage. |
Conclusion
Removing negative content from the Internet is crucial in today’s complex online landscape. While the Internet has made reputation management more challenging, it also offers powerful tools for companies to engage with customers and protect their image. No business wants negative stories to be the first result in a Google search. Having a proactive plan to mitigate such risks—whether by removing harmful links or pushing positive content—is essential. Partner with a reputation management company to anticipate threats and let experts handle the response efficiently.
Frequently Asked Questions (FAQ)
What is the best way to remove negative information from the internet?
To remove harmful content, first contact the publisher or site owner and request removal or correction. If that fails, use Google’s removal tools or legal options to take down false or defamatory material. You may also work with online reputation experts to suppress negative links through positive SEO.
Why is removing negative content important for lawyers?
Negative content can damage credibility and erode client trust. Since most clients research lawyers online, harmful information can deter new business. Removing or addressing such content preserves reputation and professional integrity.
How to remove my information from the internet?
Use Google’s personal information removal tools and opt out of data brokers like Spokeo or MyLife or leverage professional services.
How can I remove negative information or fake reviews?
Report fake or defamatory reviews to the platform for removal and provide evidence if possible. Consistently encourage satisfied clients to share authentic feedback to outweigh false claims. Reputation management firms can assist in minimizing the impact of persistent or damaging reviews.
Removing Negative Content Online Is One of the Simplest Ways to Restore Your Online Reputation.
Get in Touch With Us Today to Start Repairing Your Reputation!
Request a Call BackSend Us an EmailRecommended Reads

OnlyFans Reputation Management | Protect Your Image & Earnings
Read More
How to Remove Airbnb Reviews: A Complete Guide for Success
Read More
PeekYou Removal: Complete Guide to Opting Out Safely
Read More
About
Capabilities
Consulting
Quick Links
Stay Updated
Name(Required)Email(Required) CaptchaStar Rating
370 Reviews![]()








- Pay Now
Powered By: Girl Power Talk
Copyright 2026. All Rights Reserved. Blue Ocean Global Technology.
Powered by ConveyThis Spanish EnglishTag » How To Remove Bad Internet Posts
-
12 Steps For Removing Content From The Internet - Minc Law
-
How To Get Something Removed From Google Search – The Five Ways
-
How To Remove Negative Content From Google Search
-
How To Remove Negative Information From The Internet {2022 ...
-
How To Remove Something From The Internet - Reputation911
-
Three Steps To Removing Negative Search Results - ReputationDefender
-
What To Know About Removing Negative Articles From The Internet
-
How To Remove Negative Information From The Internet? - Prodima
-
10 Actionable Ways To Remove Negative Content From Google Search
-
How To Remove Content About You From The Internet | Adlex
-
Dealing With Negative Search Results: How To Get Rid Of The Bad Stuff
-
How To Remove News Articles From The Internet - QuickSprout
-
Removing Content Online, Delete Negative Content | Igniyte