What Is Convolutional Neural Network? - Definition From
Unpacking the architecture of a CNN
A CNN typically consists of several layers, which can be broadly categorized into three groups: convolutional layers, pooling layers and fully connected layers. As data passes through these layers, the complexity of the CNN increases, which lets the CNN successively identify larger portions of an image, as well as more abstract features.
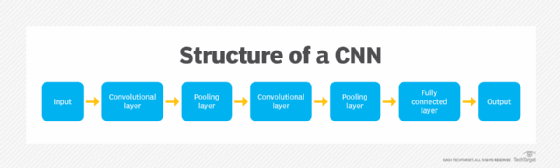
Convolutional layer
The convolutional layer is the fundamental portion of a CNN and is where the majority of computations happen. This layer uses a filter or kernel -- a small matrix of weights -- to move across the receptive field of an input image to detect the presence of specific features.
The process begins by sliding the kernel over the image's width and height, eventually sweeping across the entire image over multiple iterations. At each position, a dot product is calculated between the kernel's weights and the pixel values of the image under the kernel. This transforms the input image into a set of feature maps or convolved features, each of which represents the presence and intensity of a certain feature at various points in the image.
CNNs often include multiple stacked convolutional layers. Through this layered architecture, the CNN progressively interprets the visual information contained in the raw image data. In the earlier layers, the CNN identifies basic features, such as edges, textures or colors. Deeper layers receive input from the feature maps of previous layers, enabling them to detect more complex patterns, objects and scenes.
Pooling layer
The pooling layer of a CNN is a critical component that follows the convolutional layer. Similar to the convolutional layer, the pooling layer's operations involve a sweeping process across the input image, but its function is otherwise different.
The pooling layer aims to reduce the dimensionality of the input data, while retaining critical information, thus improving the network's overall efficiency. This is typically achieved through downsampling, which is the number of data points in the input.
For CNNs, this typically means reducing the number of pixels used to represent the image. The most common form of pooling is max pooling, which retains the maximum value within a certain window -- i.e., the kernel size -- while discarding other values. Another common technique, known as average pooling, takes a similar approach but uses the average value instead of the maximum.
Downsampling significantly reduces the overall number of parameters and computations. In addition to improving efficiency, this strengthens the model's generalization ability. Less complex models with higher-level features are typically less prone to overfitting -- an occurrence where a model learns noise and overly specific details in its training data, negatively affecting its ability to generalize to new, unseen information.
Reducing the spatial size of the representation does have a potential downside, namely the loss of some information. However, learning only the most prominent features of the input data is usually sufficient for tasks such as object detection and image classification.
Fully connected layer
The fully connected layer plays a critical role in the final stages of a CNN, where it is responsible for classifying images based on the features extracted in the previous layers. The term fully connected means that each neuron in one layer is connected to each neuron in the subsequent layer.
The fully connected layer integrates the various features extracted in the previous convolutional and pooling layers and maps them to specific classes or outcomes. Each input from the previous layer connects to each activation unit in the fully connected layer, enabling the CNN to simultaneously consider all features when making a final classification decision.
Not all layers in a CNN are fully connected. Because fully connected layers have many parameters, applying this approach throughout the entire network creates unnecessary density, increases the risk of overfitting and makes the network expensive to train in terms of memory and compute. Limiting the number of fully connected layers balances computational efficiency and generalization ability with the capability to learn complex patterns.
Additional layers
The convolutional, pooling and fully connected layers are all considered to be the core layers of a CNN. There are, however, additional layers that a CNN might have:
- The activation layer is a commonly added and equally important layer in a CNN. The activation layer enables nonlinearity -- meaning the network can learn more complex (nonlinear) patterns. This is crucial for solving complex tasks. This layer often comes after the convolutional or fully connected layers. Common activation functions include the ReLU, Sigmoid, Softmax and Tanh functions.
- The dropout layer is another added layer. The goal of the dropout layer is to reduce overfitting by dropping neurons from the neural network during training. This reduces the size of the model and helps prevent overfitting.
Tag » Cnn V C Be
-
CNN International - Breaking News, US News, World News And Video
-
CNN Video Experience
-
Breaking News, Latest News And Videos - CNN International
-
Videos - CNN Business
-
Latest News Videos - CNN
-
CNN - YouTube
-
CNN Breaks Down Key Moments In The 77-minute Surveillance Video ...
-
The CNN Video Collection | Alexander Street
-
Convolutional Neural Network - Wikipedia
-
RISC-V CNN Coprocessor For Real-Time Epilepsy Detection In ...
-
Producer, CNN Video Programming - WarnerMedia Careers
-
Solved: Embedding A CNN Video? - Instructure Community
-
Convolutional Neural Network (CNN) - NVIDIA Developer