Deep Learning Based Approach Implemented To Image Super ...
- Log In
- Sign Up
- more
- About
- Press
- Papers
- Terms
- Privacy
- Copyright
- We're Hiring!
- Help Center
- less
Outline
keyboard_arrow_downTitleAbstractKey TakeawaysIntroductionRelated WorksMethodConclusionReferencesFAQsAll TopicsComputer ScienceInformation Systems
Download Free PDF
Download Free PDFDeep Learning Based Approach Implemented to Image Super-Resolution TUAN NGUYEN THANH
TUAN NGUYEN THANHJournal of Advances in Information Technology
https://doi.org/10.12720/JAIT.11.4.209-216visibility…
description8 pages
descriptionSee full PDFdownloadDownload PDF bookmarkSave to LibraryshareSharecloseSign up for access to the world's latest research
Sign up for freearrow_forwardcheckGet notified about relevant paperscheckSave papers to use in your researchcheckJoin the discussion with peerscheckTrack your impactAbstract
The aim of this research is about application of deep learning approach to the inverse problem, which is one of the most popular issues that has been concerned for many years about, the image Super-Resolution (SR). From then on, many fields of machine learning and deep learning have gained a lot of momentum in solving such imaging problems. In this article, we review the deep-learning techniques for solving the image super-resolution especially about the Generative Adversarial Network (GAN) technique and discuss other ways to use the GAN for an efficient solution on the task. More specifically, we review about the Enhanced Super-Resolution Generative Adversarial Network (ESRGAN) and Residual in Residual Dense Network (RRDN) that are introduced by 'idealo' team and evaluate their results for image SR, they had generated precise results that gained the high rank on the leader board of state-of-the-art techniques with many other datasets like Set5, Set14 or DIV2K, etc. To be more specific, we will also review the Single-Image Super-Resolution using Generative Adversarial Network (SRGAN) and the Enhanced Super-Resolution Generative Adversarial Networks (ESRGAN), two famous state-of-the-art techniques, by retrain the proposed model with different parameter and comparing with their result. So that can be helping us understand the working of announced model and the different when we choose others parameter compared to theirs.
... Read moreKey takeaways
AI
- Deep Learning techniques, especially GANs, significantly enhance image Super-Resolution (SR) performance.
- The study reviews ESRGAN and RRDN, achieving high PSNR values around 34.22 and competitive results on datasets like DIV2K.
- SISR methods outperform traditional techniques like bicubic interpolation, demonstrating superior detail recovery capabilities.
- The training utilized the DIV2K dataset, containing 800 high-quality images with diverse details and various scaling factors.
- Future enhancements include denoising datasets and incremental learning for better image quality in SR tasks.
Related papers
Deep Generative Adversarial Residual Convolutional Networks for Real-World Super-ResolutionRao Umer2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2020
Most current deep learning based single image superresolution (SISR) methods focus on designing deeper / wider models to learn the non-linear mapping between lowresolution (LR) inputs and the high-resolution (HR) outputs from a large number of paired (LR/HR) training data. They usually take as assumption that the LR image is a bicubic down-sampled version of the HR image. However, such degradation process is not available in real-world settings i.e. inherent sensor noise, stochastic noise, compression artifacts, possible mismatch between image degradation process and camera device. It reduces significantly the performance of current SISR methods due to real-world image corruptions. To address these problems, we propose a deep Super-Resolution Residual Convolutional Generative Adversarial Network (SRResCGAN 1) to follow the real-world degradation settings by adversarial training the model with pixel-wise supervision in the HR domain from its generated LR counterpart. The proposed network exploits the residual learning by minimizing the energy-based objective function with powerful image regularization and convex optimization techniques. We demonstrate our proposed approach in quantitative and qualitative experiments that generalize robustly to real input and it is easy to deploy for other downscaling operators and mobile/embedded devices.
downloadDownload free PDFView PDFchevron_rightImage super resolution using Generative Adversarial NetworkIRJET JournalIRJET, 2022
Super-resolution (SR) is an image processing technique that aims to increase the resolution of an image by adding sub-pixel detail. The information used for adding detail can come from sub-pixel shifts provided by sequences of images (frequency domain), or by a good understanding of the degradation processes, including blurring, that cause the loss of detail. Convolutional neural networks (CNNs) are especially suited for this type of application due to their ability to empirically map the underlying connections between an image pixel and those surrounding it. Conversion from multiple low resolution (LR) images to high resolution (HR) image is done by using super-resolution techniques. Anyone can achieve more information in detail from high-resolution images, which helps further for many satellite image applications. This growing technology interest in the reconstruction of imagery leads to several methodologies in the field of advanced digital color image processing. Recent years have seen growing interest in the problem of super-resolution restoration of video sequences. Whereas in the traditional single image restoration problem only a single input image is available for processing, the task of reconstructing super-resolution images from multiple under sampled and degraded images can take advantage of the additional patiotemporal data available in the image sequence. In particular, camera and scene motion lead to frames in the source video sequence containing similar, but not identical information. The additional information available in these frames make possible reconstruction of visually superior frames at higher resolution than that of the original data.
downloadDownload free PDFView PDFchevron_rightSRDGAN: learning the noise prior for Super Resolution with Dual Generative Adversarial Networkssongnan liArXiv, 2019
Single Image Super Resolution (SISR) is the task of producing a high resolution (HR) image from a given low-resolution (LR) image. It is a well researched problem with extensive commercial applications such as digital camera, video compression, medical imaging and so on. Most super resolution works focus on the features learning architecture, which can recover the texture details as close as possible. However, these works suffer from the following challenges: (1) The low-resolution (LR) training images are artificially synthesized using HR images with bicubic downsampling, which have much richer-information than real demosaic-upscaled mobile images. The mismatch between training and inference mobile data heavily blocks the improvement of practical super resolution algorithms. (2) These methods cannot effectively handle the blind distortions during super resolution in practical applications. In this work, an end-to-end novel framework, including high-to-low network and low-to-high ne...
downloadDownload free PDFView PDFchevron_rightSRPGAN: Perceptual Generative Adversarial Network for Single Image Super ResolutionHaodong DuanArXiv, 2017
Single image super resolution (SISR) is to reconstruct a high resolution image from a single low resolution image. The SISR task has been a very attractive research topic over the last two decades. In recent years, convolutional neural network (CNN) based models have achieved great performance on SISR task. Despite the breakthroughs achieved by using CNN models, there are still some problems remaining unsolved, such as how to recover high frequency details of high resolution images. Previous CNN based models always use a pixel wise loss, such as l2 loss. Although the high resolution images constructed by these models have high peak signal-to-noise ratio (PSNR), they often tend to be blurry and lack high-frequency details, especially at a large scaling factor. In this paper, we build a super resolution perceptual generative adversarial network (SRPGAN) framework for SISR tasks. In the framework, we propose a robust perceptual loss based on the discriminator of the built SRPGAN model....
downloadDownload free PDFView PDFchevron_rightDVDR-SRGAN: Differential Value Dense Residual Super-Resolution Generative Adversarial Networkhuawei yiSensors
In the field of single-image super-resolution reconstruction, GAN can obtain the image texture more in line with the human eye. However, during the reconstruction process, it is easy to generate artifacts, false textures, and large deviations in details between the reconstructed image and the Ground Truth. In order to further improve the visual quality, we study the feature correlation between adjacent layers and propose a differential value dense residual network to solve this problem. We first use the deconvolution layer to enlarge the features, then extract the features through the convolution layer, and finally make a difference between the features before being magnified and the features after being extracted so that the difference can better reflect the areas that need attention. In the process of extracting the differential value, using the dense residual connection method for each layer can make the magnified features more complete, so the differential value obtained is more...
downloadDownload free PDFView PDFchevron_rightReal-World Super-Resolution using Generative Adversarial NetworksAmin Kheradmand2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2020
Robust real-world super-resolution (SR) aims to generate perception-oriented high-resolution (HR) images from the corresponding low-resolution (LR) ones, without access to the paired LR-HR ground-truth. In this paper, we investigate how to advance the state of the art in real-world SR. Our method involves deploying an ensemble of generative adversarial networks (GANs) for robust real-world SR. The ensemble deploys different GANs trained with different adversarial objectives. Due to the lack of knowledge about the ground-truth blur and noise models, we design a generic training set with the LR images generated by various degradation models from a set of HR images. We achieve good perceptual quality by super resolving the LR images whose degradation was caused by unknown image processing artifacts. For real-world SR on images captured by mobile devices, the GANs are trained by weak supervision of a mobile SR training set having LR-HR image pairs, which we construct from the DPED datas...
downloadDownload free PDFView PDFchevron_rightAdvanced Single Image Resolution Upsurging Using A Generative Adversarial NetworkMoshiur RahmanSignal & Image Processing : An International Journal, 2020
The resolution of an image is a very important criterion for evaluating the quality of the image. Higher resolution of image is always preferable as images of lower resolution are unsuitable due to fuzzy quality. Higher resolution of image is important for various fields such as medical imaging; astronomy works and so on as images of lower resolution becomes unclear and indistinct when their sizes are enlarged. In recent times, various research works are performed to generate higher resolution of an image from its lower resolution. In this paper, we have proposed a technique of generating higher resolution images form lower resolution using Residual in Residual Dense Block network architecture with a deep network. We have also compared our method with other methods to prove that our method provides better visual quality images.
downloadDownload free PDFView PDFchevron_rightGenerative adversarial networks for single image super resolution in microscopy imagesSaurabh Gawande2018
Image Super resolution is a widely-studied problem in computer vision, where the objective is to convert a lowresolution image to a high resolution image. Conventional methods for achieving super-resolution such as image priors, interpolation, sparse coding require a lot of pre/post processing and optimization. Recently, deep learning methods such as convolutional neural networks and generative adversarial networks are being used to perform super-resolution with results competitive to the state of the art but none of them have been used on microscopy images. In this thesis, a generative adversarial network, mSRGAN, is proposed for super resolution with a perceptual loss function consisting of a adversarial loss, mean squared error and content loss. The objective of our implementation is to learn an end to end mapping between the low / high resolution images and optimize the upscaled image for quantitative metrics as well as perceptual quality. We then compare our results with the current state of the art methods in super resolution, conduct a proof of concept segmentation study to show that super resolved images can be used as a effective pre processing step before segmentation and validate the findings statistically.
downloadDownload free PDFView PDFchevron_rightEnhanced Face Image Super-Resolution Using Generative Adversarial NetworkElvianto Dwi HartonoPenelitian ilmu komputer sistem embedded & logic, 2022
We proposed an Enhanced Face Image Generative Adversarial Network (EFGAN). Single image superresolution (SISR) using a convolutional is often a problem in enhancing more refined texture upscaling factors. Our approach focused on mean square error (MSE), validation peak-signal-to-noise ratio (PSNR), and Structural Similarity Index (SSIM). However, the peak-signal-to-noise ratio has a high value to detail. The generative Adversarial Network (GAN) loss function optimizes the super-resolution (SR) model. Thus, the generator network is developed with skip connection architecture to improve performance feature distribution.
downloadDownload free PDFView PDFchevron_rightImage Super-Resolution using Convolutional Neural NetworksRupesh SushirInternational Journal of Advanced Research in Science, Communication and Technology, 2024
Image super-resolution is the process of enhancing the resolution of an image, typically from a lower resolution input to a higher resolution output. This research aims to explore the application of convolutional neural networks (CNNs) for image super-resolution. Specifically, the study will focus on developing a deep learning model capable of generating high-resolution images from low-resolution inputs. Various CNN architectures, such as SRCNN (Super-Resolution Convolutional Neural Network) or SRGAN (Super-Resolution Generative Adversarial Network), will be investigated and compared for their effectiveness in producing visually pleasing and perceptually accurate high-resolution images. Additionally, techniques such as residual learning, attention mechanisms, and adversarial training may be incorporated to further improve the quality of super-resolved images. The performance of the proposed models will be evaluated using standard image quality metrics and subjective assessments. This research has practical applications in enhancing the visual quality of low-resolution images in fields such as medical imaging, surveillance, and entertainment.
downloadDownload free PDFView PDFchevron_rightSee full PDFdownloadDownload PDFDeep Learning Based Approach Implemented to Image Super-Resolution
Thuong Le-Tien, Tuan Nguyen-Thanh, Hanh-Phan Xuan, Giang Nguyen-Truong, and Vinh Ta-Quoc Ho Chi Minh City University of Technology (HCMUT), 268 Ly Thuong Kiet Street, District 10, Ho Chi Minh City, VietnamVietnam National University Ho Chi Minh City (VNU-HCM), Linh Trung Ward, Thu Duc District, Ho Chi Minh City, VietnamEmail: {thuongle, nttuan}@hcmut.edu.vn, {phantyp, ntg2208, taquocvinhbk10}@ gmail.com
Abstract
The aim of this research is about application of deep learning approach to the inverse problem, which is one of the most popular issues that has been concerned for many years about, the image Super-Resolution (SR). From then on, many fields of machine learning and deep learning have gained a lot of momentum in solving such imaging problems. In this article, we review the deep-learning techniques for solving the image super-resolution especially about the Generative Adversarial Network (GAN) technique and discuss other ways to use the GAN for an efficient solution on the task. More specifically, we review about the Enhanced Super-Resolution Generative Adversarial Network (ESRGAN) and Residual in Residual Dense Network (RRDN) that are introduced by ‘idealo’ team and evaluate their results for image SR, they had generated precise results that gained the high rank on the leader board of state-of-the-art techniques with many other datasets like Set5, Set14 or DIV2K, etc. To be more specific, we will also review the Single-Image Super-Resolution using Generative Adversarial Network (SRGAN) and the Enhanced SuperResolution Generative Adversarial Networks (ESRGAN), two famous state-of-the-art techniques, by re-train the proposed model with different parameter and comparing with their result. So that can be helping us understand the working of announced model and the different when we choose others parameter compared to theirs.
Index Terms-image super-resolution, deep learning, inverse problems, Residual in Residual Dense Network (RRDN), Generative Adversarial Network (GAN), Enhanced Super-Resolution Generative Adversarial Networks (ESRGAN)
I. INTRODUCTION
The fundamental concept of Artificial Intelligence (AI), including Machine Learning and Deep Learning, has been implemented to various fields gained many achievements. Unlike analytical methods for which the problem is explicitly defined and domain-knowledge carefully engineered into solution, Deep Neural Networks (DNNs) do not benefit from such prior know instead make use of large data sets to learn the unknown solution to the inverse problem. The inverse problem has defined by Lucas et al. 2018 [1] that has a long history of
[1]research and development. These inverse problems are also known as recovery problems: restoration, deconvolution, inpainting, reconstruction from projections, compressive sensing, Super-Resolution (SR), etc. The solutions for inverse problems have been raised for many years with many different methods. But with the support of Neural Network recently, the solutions are more specific and efficient in the way that DNNs has gave us. In the deep-learning literature, such modules are commonly referred to as layers, and each layer is composed of multiple units or neurons, that makes the model easier to extract the feature of the input for solving the data that relate to ground truth. Super-resolution is the process of recovering a High Resolution (HR) image from a given Low Resolution (LR) image [2]. An image may have a “lower resolution” due to a smaller spatial resolution or due to a result of degradation. When we use the degradation, function is scale down the image resolution, we obtain the LR data from the HR. The inverse problem is the solution that make the LR back to HR as much similarly as possible. Deep Learning techniques have proven to be effective for Super Resolution by given a method that was trained times by times with the dataset concludes HR and LR that are downscaled from HR. There has been much studies in recent decades, with significant progress results with many methods. In the demand of human about the superresolution image nowadays is very important because of the detail of information in many fields of science. A better detail of the images, the more feature that we get. Such as the television every day we watch required more and more detail with quality of vision about 4 K or more than that. The better the image quality, the more comfortable our eyes will be and the less myopia will occur. Another vision that image super-resolution has the effect on is in medical, whether the doctor can recognize exactly the size of the tumor or other pathological. That need the exact detail in order to give the precise decision. Not only these fields, but also another like in agriculture, military and traffic for example. In China, recently, they have taken a picture 195 gigapixels from satellite by quantum technology which is from space can zoom scale up to the street in the Shanghai’s city with every single particular detail about the sign of the cars, the numbers or
Manuscript received May 22, 2020; revised September 29, 2020. ↩︎
even the human’s faces. In Vietnam recently, by photographer Binh Bui had showed down the picture about Hanoi capital with 13 gigapixels [3]. With the crucial of the super-resolution images, many methods were established to generate image SR.
II. Related Works
The Image Super-resolution processing that are considered as two type: Single Image Super-Resolution (SISR) and Multiple Image or multi-frame images. In this paper, we focus on the SISR with techniques used DL Network that will be discussed in detail. For the construction image super-resolution methods, Zhu et al. [4] has introduced about the reconstruction image SR based on sparse representation via direction and edge, direction. With SISR the experimental setting that has achieved much better PSNR and SSIM index than bicubic and NCSR. With the same method Jiang et al. [5] applied for image in medical fields, CT images and proved that their method was effectively improve the resolution of a single CT image. In 2007, Sinh Nguyen L. H. et al. [6] made an experiment about the heterogeneous interpolation and filter to reconstruct image HR in several of interpolation methods. Another SISR that is about the combination of frequency domain and wavelet domain to reconstruct the image super-resolution of Thuong LeTien et al. [7] in 2009. On the other hand of reconstruction image SR, Deep Learning method has been experienced with many significant results. Recently, Yang et al. [8] has introduced about the SRCNN for upscaling LR image into HR image and gained good result, they also reported that the acceleration of deep models and extensive comprehension of deep models and the criteria for designing and evaluation the objective functions are their challenges for optimizing their model. Similarly, Kawulof et al. [9] has applied Deep learning for Multi-frame Image SR and gained better results. In the appearance and improvement of Generative Adversarial Network (GAN) by Goodfellow et al. [10], many GAN methods were raised and gained better results for SISR. In 2017, Ledig et al. [11] presented SRGAN the first framework capable of inferring photo-realistic natural images for 4 x upscaling factors. With the achievement that performance on different dataset, they made a comparison of their model with PSNR or SSIM and other metrics. However, their limitation is that PSNR and SSIM fail to capture and accurate assess image quality with respect to the human visual system and confirmed that SRGAN reconstructions for large upscale factor are, by a considerable margin, more photo-realistic than reconstructions obtained with state-of-the-art reference methods. Bingzhe Wu et al. [12] introduced about the SRPGAN that contains perceptual loss based on the discriminator of the built SRPGAN and used the Charbonnier loss function to build the content loss and combine it with the proposed perceptual loss and the adversarial loss. They had mad comparison with SRGAN and show that their model has a better job with the same scaling factor of 4 x . The limitation of their method is constructed images have checkerboard artifacts at the pixel level. In March 2018 Zhang et al. [13] represented about the model that has the Residual Dense Block (RBD) for feature extraction capture and made Residual Dense Network to generate image and calculated loss. That extensive benchmark evaluation well demonstrates their model achieves superiority over state-of-the-art. In September of 2018, with the RDN, Xintao Wang et al. [14] made Residual in Residual Dense Network (RRDN) and Enhanced SR Network (ESRGAN) that gained state-of-the-art that generated better results than SRGAN. In this paper, we review about the RRDN technique and evaluate the result that experienced.
III. METHOD A. Algorithm
Fig. 1 is the algorithm flow chart; the Low-resolution images will be fed over the generator to create the Superresolution images output. Then the SR images will be distinguished with HR image from the ground truth to find whether the SR image is well generated closer to the ground truth or not.
The loss is calculated by the feature maps of the SR passed through the discriminator and the other is the HR image will be extracted the feature maps by the VGG model. The loss will be then updated for generator to adjust the SR images to be as the most similar as the HR. The losses of the generator and the discriminator are then back propagation for update the process. At the final, these losses will gain the value of the middle means that the discriminator cannot distinguish the generated images and the generator is also converged. 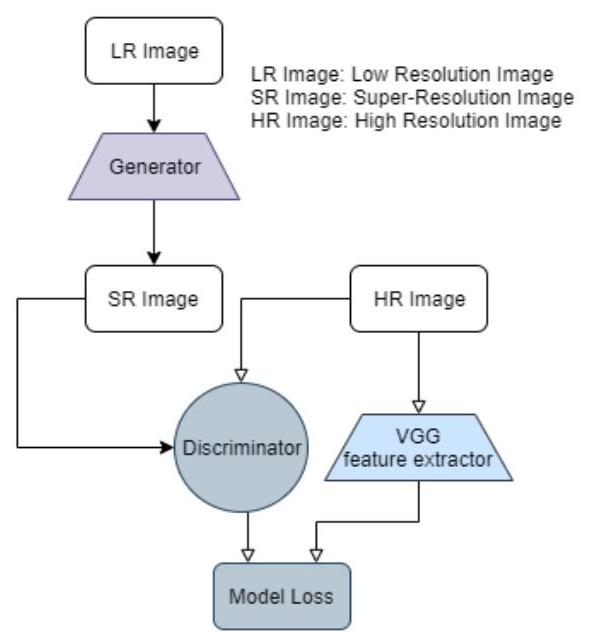
Figure 1. The algorithm flow chart for GAN process to generate the super-resolution images.
B. Network Architecture
In other to improve recovered image quality of SRGAN, Wang [14] had introduced about the Residual in Residual Dense Block (RRDB) with removal all BN layers that proved the increase performance and reduce
computational complexity in different PSNR-oriented tasks including SR and deblurring. BN layers normalize the features using mean and variance in a batch during training and use estimated mean and variance of the whole training dataset during testing. As shown in Fig. 2, the RRDN mainly consists four parts: Shallow Feature Extraction (SFENet), Residual Dense Blocks (RDBs), Dense Feature Fusion (DFF) and finally the up-sampling net (UPNet). By replacing RDB block with RRDB block that Wang [14] has introduced in their method. The RRDB contains dense connected layers, Local Feature Fusion (LFF) and local residual learning, leading to a contiguous memory mechanism. 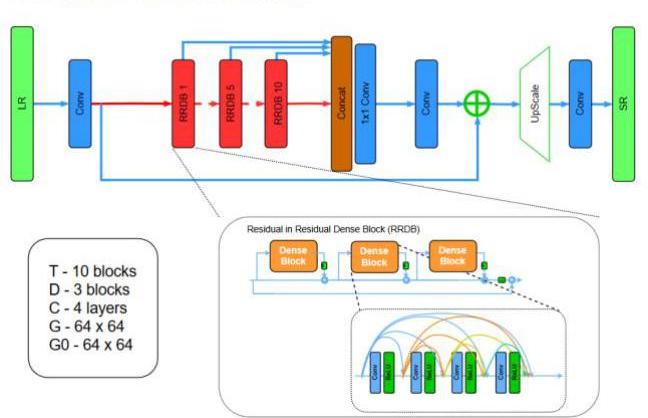
Figure 2. Residual in Residual Dense Block (RRDB) with BN removal [14].
C. Residual Dense Blocks
Local feature fusion: adaptively fuse the states from proceeding RRDB and whole Conv layers in current RRDB.
Fd,LF=HLFFd([Fd−1,Fd,1,…,Fd,c,…,Fd,c])F_{d, L F}=H_{L F F}^{d}\left(\left[F_{d-1}, F_{d, 1}, \ldots, F_{d, c}, \ldots, F_{d, c}\right]\right)
where HLFFdH_{L F F}^{d} denotes the function of the 1×11 \times 1 Conv layer in the d-th RRDB, Fd−1,Fd,1F_{d-1}, F_{d, 1}, etc is input and output of the d-th RDB respectively.
Local residual learning: is introduced in RDB [11] to further improve the information flow. The final output of the d-th RDB can be obtained:
Fd=Fd−1+Fd,LFF_{d}=F_{d-1}+F_{d, L F}
D. Dense Feature Fusion
Global feature fusion: is proposed as shown in Fig. 3 to extract the global feature FGFF_{G F} by using features from all the RDBs:
Fd,LF=HGFF([F1,…,FD])F_{d, L F}=H_{G F F}\left(\left[F_{1}, \ldots, F_{D}\right]\right)
where [F1,…,FD]\left[F_{1}, \ldots, F_{D}\right] refers to the concatenation of featuremaps produced by RDB 1,…,D1, \ldots, \mathrm{D}.
Global residual learning: is then utilized to obtain the feature-maps before conducting up-scaling by:
FDF=F−1+FGFF_{D F}=F_{-1}+F_{G F}
where F−1F_{-1} denotes the shallow feature-maps and FGFF_{G F} is further adaptive fused to form. 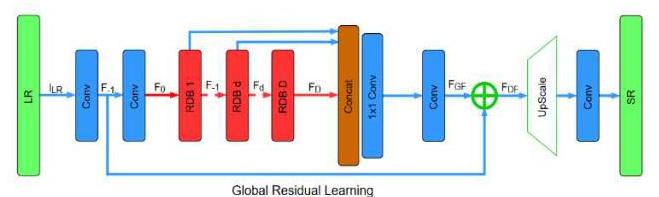
Figure 3. The architecture of our proposed Residual Dense Network (RDN) [11].
E. Relativistic Discrimination
Beside the improved structure of generator, Wang et al. [14] also enhance the discriminator based on the Relativistic GAN [15] that can be seen in Fig. 4. 
Figure 4. Difference between standard discriminator (left) and relativistic discriminator (right).
The discriminator loss is then defined as: LsiRa=−Exi[log(DRa(xr,xf))]−Exf[log(1−DRa(xf,xr))]L_{s i}^{R a}=-E_{x_{i}}\left[\log \left(D_{R a}\left(x_{r}, x_{f}\right)\right)\right]-E_{x_{f}}\left[\log \left(1-D_{R a}\left(x_{f}, x_{r}\right)\right)\right] The adversarial loss for generator is in a symmetrical form: LGRa=−Exi[log(1−DRa(xr,xf))]−Exf[log(DRa(xf,xr))]L_{G}^{R a}=-E_{x_{i}}\left[\log \left(1-D_{R a}\left(x_{r}, x_{f}\right)\right)\right]-E_{x_{f}}\left[\log \left(D_{R a}\left(x_{f}, x_{r}\right)\right)\right] where xf=G(xi)x_{f}=G\left(x_{i}\right) and xix_{i} stand for the input LR image. It observed that the adversarial loss for generator contains both xrx_{r} and xfx_{f}. Therefore, the generator benefits from the gradients from both generated data and real data in adversarial training.
F. Perceptual Loss
They had also developed a more effective perceptual loss Lperceptual L_{\text {perceptual }} by constraining on features before activation rather than after activation as practiced in SRGAN.
The total loss for the generator is:
LG=Lpercep +λLGRa+ηL1L_{G}=L_{\text {percep }}+\lambda L_{G}^{R a}+\eta L_{1}
where L1=Ex1∥G(xi)−y∥1L_{1}=E_{x_{1}}\left\|G\left(x_{i}\right)-y\right\|_{1} is the content loss that evaluate the 1 -norm distance between recovered image G(xi)G\left(x_{i}\right) and the ground truth y and λ,η\lambda, \eta are the coefficients to balance different loss terms.
G. Content Loss
The pixel-wise MSE loss is calculated as:
ParseError: KaTeX parse error: Expected 'EOF', got '\right' at position 130: …}\right)_{x, y}\̲r̲i̲g̲h̲t̲)^{2}
where GθG(lLR)G_{\theta_{G}}\left(l^{L R}\right) is the reconstructed image and lx,yHRl_{x, y}^{H R} followed by a down sampling operation with down sampling factor r . This is the most widely used optimization target for image SR on which many state-of-the-art approaches rely. As Ledig, instead of relying on pixel-wise losses, they had built the ideas that definition of VGG loss. VGG loss based on the ReLU activation layers of the pre-trained 19-layer VGG network. They
defined the VGG loss as the Euclidean distance between the feature representations of a reconstructed image GθG(ILR)G_{\theta_{G}}\left(I^{L R}\right) and the reference IHRI^{H R} : 1Wi,jHi,j∑x=1∞∑y=1Hi,j(ϕi,j(IHR)x,y−ϕi,j(GθG(ILR))x,y)2\frac{1}{W_{i, j} H_{i, j}} \sum_{x=1}^{\infty} \sum_{y=1}^{H_{i, j}}\left(\phi_{i, j}\left(I^{H R}\right)_{x, y}-\phi_{i, j}\left(G_{\theta_{G}}\left(I^{L R}\right)\right)_{x, y}\right)^{2}
IV. RESULTS
For training data, we mainly use the DIV2K dataset. This dataset contains high quality dataset with 2 K resolution for image restoration tasks, which are about 800 images with many different details like animals, human, nature views, etc. The whole dataset has variety of scaling factors that we can use 2x,4x,3x2 \mathrm{x}, 4 \mathrm{x}, 3 \mathrm{x} and 8 x with scale down method is mainly bicubic. Besides, there are validation dataset about 200 images for the validation task to predict the process that corresponds to training set.
By applying model of Wang et al., we can set the parameter: C: 4, D: 3, G: 64, G0: 64, T: 10 and the scale factor is 2x2 x. Where the parameters were defined by idealo’s team as C is the number of convolutional layers stacked inside a RDB, T is the number of Residual in Residual Dense Blocks, D is the number of Residual Dense Blocks inside each RRDN, G and G0 are the number of the feature maps of each convolutional layers inside RDBs and feature maps for convolutions outside of RDBs and of each RDB output respectively. 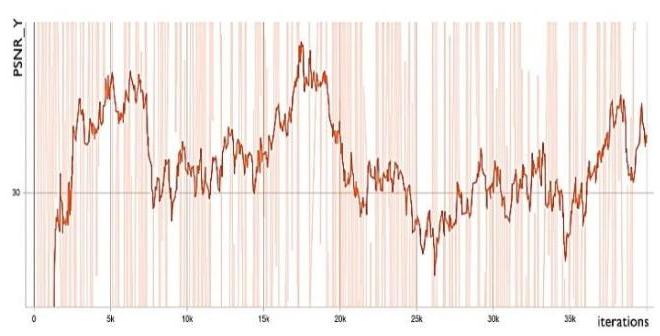
Figure 5. Train PSNR_Y. The training process takes hours for training with learning rate: 5e-4 the decay factor is 0.5 and decay frequency is 30 . We trained 80 epochs with step per epochs 500 iterations and batch size is 16 . The metric for optimize is PSNR. After 80 epochs we got the validation PSNR is quite acceptable 32 and the train PSNR_Y was 44 at the peak as shown in Fig. 5 and Fig. 6. 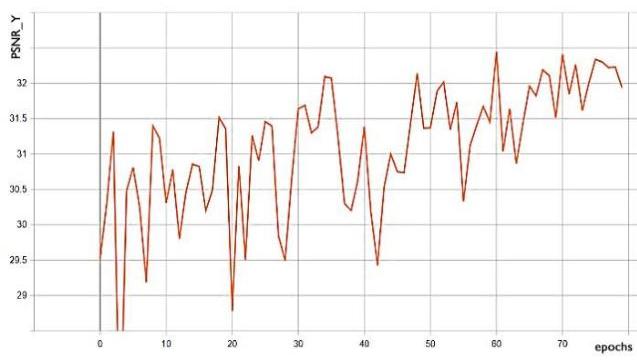
Figure 6. Valid PSNR_Y.
For that PSNR we use tensor-board that is supported by tensor-flow framework and set the smooth weight to 0.82 for better observation. The PSNR_Y increases showed that the generated SR images look closer and closer to the original HR images. We need to maximize the loss function of discriminator. After 40 thousand of steps or iterations, the discriminator started to be unchanged. The model started to converge and no overfit occurred. Our final training PSNR_Y gained 34.22 which is acceptable compared to current state-of-the-art in image super-resolution.
We can see from the Fig. 7 and Fig. 8 about the loss of the generator over the training and validation process. The training process loss is fluctuated, because the generated images fed to the discriminator, the fluctuation means that the discriminator recognized the fake images compared with the ground truth, then generator has to adjust to create better images. 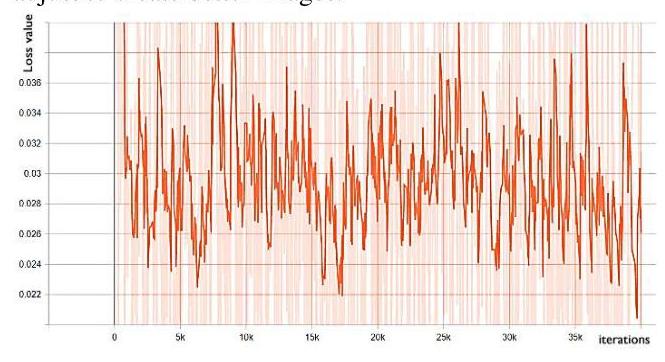
Figure 7. Train generator loss. 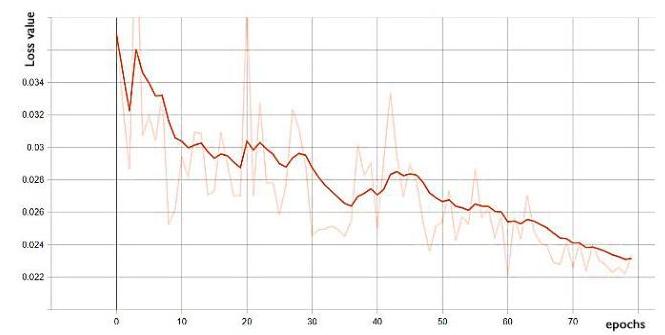
Figure 8. Valid generator loss. The discriminator losses in both training and validation process in Fig. 9 and Fig. 10 are seen to be unstable. The training process loss trends to decrease to the middle value which is explained that the discriminator is going not to be able to recognize which is fake images from generator and the ground truth images. 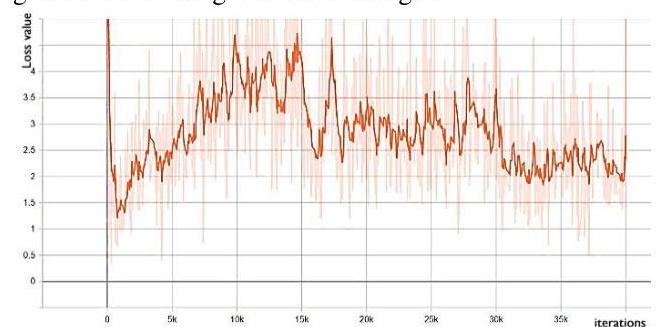
Figure 9. Train discriminator loss.
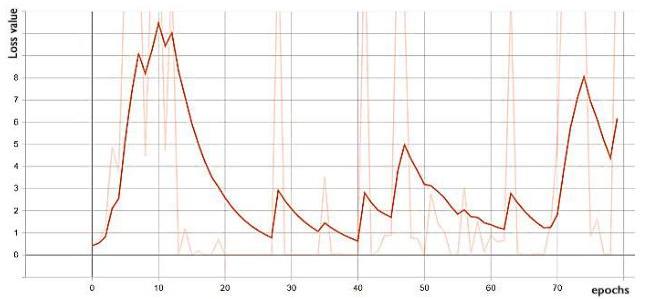
Figure 10. Valid discriminator loss. We can see that the loss of the validation generator is reduce by epochs and the loss of the train generator is fluctuated by iterations due to the improvement of fake image generation in generator. And the discriminator loss is fluctuated in the between of the graph that is the discriminator is unable to classified whether the real image or the fake image generated by the generator. The train_d_fake_accuracy in Fig. 11 is close to 1 and train_d_fake_loss in Fig. 12 is close to 0 to show exactly the results of the model. With the similar of the accuracy and the loss, we can see that wherever the accuracy increases close to 1 , the loss decreases close to 0 and oppositely that wherever the accuracy reduces, the loss also increases significantly. 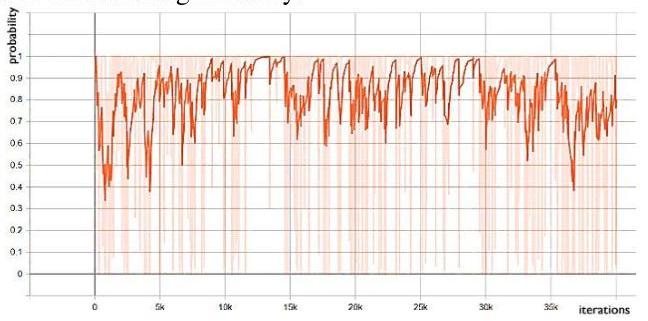
Figure 11. Train d_fake_accuracy. 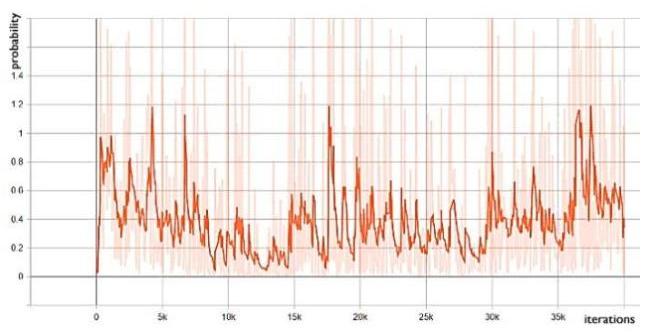
Figure 12. Train d_fake_loss. 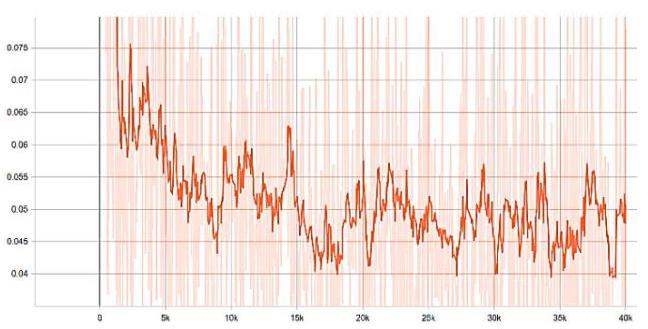
Figure 13. Train generator loss with scale factor x 4 .
The Fig. 13 showed us the generator loss with scale factor x 4 . We can see that the loss line is steadily decrease along to the 40 k iterations. Thus, the operation of model is quite good as the expectation.
The dataset we trained and predicted is high quality with many subjects and variety of sceneries. With scale factor of 2x2 x we put an image in validation set with size 192x255x3 and got the result of the picture with size 384×510×3384 \times 510 \times 3 in detail. To make a comparison with the result, we use the bicubic scaling method to up-scale the input again to double of the size. Our prediction is the bicubic method will scale up the images with lossy detail and it is not as clear as the model’s results. Then we tried to create the precise of the model with other inputs, which is not in the dataset to prove that whether the model can give the suitable results or not.
TABLE I. THE TRANING RESULTS OF TWO SCALING FACTORS WITH PSNR METRIC VALUES
| Scale | PSNR_x2 | PSNR_x4 | |
|---|---|---|---|
 | Bicubic | 29.83 | 25.75 |
| SRGAN | 29.54 | 21.62 | |
| ESRGAN | 30.13 | 24.64 | |
 | Bicubic | 24.84 | 21.83 |
| SRGAN | 24.48 | 20.19 | |
| ESRGAN | 24.62 | 20.84 |
Table I compares Average PSNR on validation data set with 100 Low-Resolution images which were down sample by “Bicubic down sampling method” and “Unknown down sampling method”. In “Bicubic down sampling” data set, ESRGAN achieve highest average PSNR with x2 up sampling, even higher than the bicubic up sample itself. In contrast, SRGAN have lower in most of the time we test, but it is able to re-create the scaled Super-Resolution image. SRGAN have a low performance in most of the evaluation process, it shows that in order for the neural network to work well, we need to use a suitable loss function. In the x 4 section is where the different between 3 methods is shown clearly, in the calculated number as well as in the demo pictures as we can see that, bicubic have higher PSNR and SSIM but the neural network to keep more details than and better visualization.
As we see from Table II, the parameters of two models are different to each other. The SRGAN has fewer parameter than ESRGAN due to the architecture of layers and algorithm. The ESRGAN has RRDB that is the continuous RDB in SRGAN. The scale factor does not affect so much on creating the weights and parameters in these models.
TABLE II. TRANING PARAMETERS OF TWO MODELS WITH TWO SCALING FACTORS
| SRGAN | ESRGAN | |||
|---|---|---|---|---|
| Scale | X 2 | X 4 | X 2 | X 4 |
| Iterations | 40 k | 40 k | 40 k | 40 k |
| Parameters | 1,381k1,381 \mathrm{k} | 1,392k1,392 \mathrm{k} | 16,644k16,644 \mathrm{k} | 16,645k16,645 \mathrm{k} |
It can be seen in Fig. 14, which are shown the results that generated by three methods we used, the first one is bicubic scale method, second is SRGAN used RDN and the last is ESRGAN with RRDN. According to the PSNR values of the test results, we can see that with RRDN method the PSNR will higher than the others due to the residual in residual blocks in network. Although our visual to these images does not recognize the difference of these images. However, in pixel level we can know the difference of these methods. 
Figure 14. The comparison of results after trained by SRGAN (b), ESRGAN © and upscale bicubic method (a) with scaling factor x 2 .
The result is quite good compared with the bicubic scaling method to reconstruction the image that was scale down from the ground truth, the bicubic scale we can see it make the squirrel a little blurry and we got the detail with the result of the model shown in Fig. 14. Then we test the model’s process with random input that is not in the training data or validation data that is shown in Fig. 15. As the result, the model that are developed by Wang et al. has proved its efficiency with the results to be very satisfied. The results above are corresponding to the input data which is not in the dataset. Therefore, we just applied the scaling up of model with scale x 2 then the PSNR will not be calculated. To test the PSNR, first we have to scale down the input and generate by the model to get the image with the initial size and then find the PSNR metric value to compare with bicubic or other scaling methods. 
Figure 15. The input (left) with RRDN scale (above right) and bicubic (bottom right).
As we can see from Table III, the differences in numbers of layers in the model will make the differences in metric values. The ideal model of previous related project had gained the significant results in our test set. With 100 images from our test set the ‘idealo’ team’s model has gained the value of PSNR to approximate 31 and SSIM to 26 in RDN and RRDN respectively. Our model with differences in number of layers, deeper particularly, gained the results with the same value of metric PSNR and SSIM. However, due to the limitation of the training devices, we cannot train the model as long as the ‘idealo’ team did, but the gained results are approximately the same value as the ideal model. Thus, in our future work, with this expectedly results, we can make the results better by training them long enough to gain better results.
TABLE III. THE COMPARISON OF DIFFERENCES IN NUMBER OF LAYERS BETWEEN IDEALO TEAM’S AND OUR MODEL
| idealo’s RDN | Our RDN | idealo’s RDN | Our RRDN | ||
|---|---|---|---|---|---|
| C | 3 | 4 | 4 | 4 | 4 |
| D | 10 | 3 | 3 | 3 | 5 |
| G | 64 | 64 | 32 | 64 | 64 |
| G0 | 64 | 64 | 32 | 64 | 64 |
| T | - | - | 10 | 10 | 15 |
| x | 2 | 2 | 4 | 4 | 4 |
| PSNR | 30.91 | 29.54 | 26.03 | 24.64 | 23.2 |
| SSIM | 0.8016 | 0.8476 | 0.673 | 0.6755 | 0.6711 |
Furthermore, we also look to combine these results with image watermarking for practical applications, especially in medical imaging. The first approach is to evaluate and improve the robustness and capacity of the embedded information against the proposed image superresolution processing. Another way is to obtain the good
high-resolution images with high embedded information capacity.
V. CONCLUSION
As considering problem mentioned, the BN removal keeps the stability and consistence performance without artifacts. It does not decrease the performance but save the computational resources and memory usage. In this paper of research, we used the vast.ai server with 1080Ti with RAM is 16 GB that a little bit limited about the batch size and step to train carefully. Our results have reached the same quality of the Wang’s with PSNR reaching to 30 for validation test and gain good result for images that outside of the dataset and validation set. By applying RRDN model then we consider that the deeper the model is the more precise results we get. However, because the model is in the state-of-the-art of performance, then to get better results, our suggestion is about the data. Before getting into training process, dataset should be passed denoise filters in order not to generate and upscale the noisy much uncomfortable. And with the project of Jahidul et al. [16] about the underwater dataset, we suggest that the whole dataset should be classified by simple classes such as: underwater, land, animals, etc. There are many classification methods we can use like YOLO with image segmentation classification. With classes, we trained other files of weights, and before we use RRDN to test, classified the input to use the corresponding file of weight suitably. We figure out this method will give the generated images with better detail due to the similar detail they are in the class trained input. However, that will reduce the number of dataset and we need as much data as possible for each class.
Another idea is based on the trained network from smaller resolution for example: 128 to 248 to 456 , etc. By increasing the resolution gradually, the network is continuously asked to learn a much simpler piece of the overall problem. The incremental learning process greatly stabilizes training. The low-to-high resolution trend also forces the progressively grown network to focus on high level structure first and fill in the details later. This improves the quality of the final image by reducing the likelihood that the network will get some high-level structure drastically wrong. The future work of this idea is started with downscale images with multiple factor. Then we will train 16 x with 8 x , save and load weight to train next 8 x with 4 x , continuously like that until we do the train with 2 x factor. The results can obtain better quality even with upscale factor 8 x or more. The expansion of these results for image watermarking in medical imaging is also considered in further research.
CONFLICT OF INTEREST
The authors declare no conflict of interest.
AUTHOR CONTRIBUTIONS
All authors had contributed equally and approved the final version.
ACKNOWLEDGMENT
This study was partially supported by Office for International Study Programs - OISP, Department of Electrical Electronics Engineering, University of Technology, HCMUT, National University - Ho Chi Minh City (VNU).
REFERENCES
[1] A. Lucas, M. Biadis, R. Molina, and A. K. Katsaggelos, “Using deep neural networks for inverse problems in imaging,” IEEE Signal Processing Magazine, January 2018. [2] Z. Wang, J. Chen, S. C. H. Hoi, “Deep learning for image superresolution: A survey,” arXiv:1902.06068v2, Feb. 2020. [3] Ha Noi 9 gigapixel. [Online]. Available: https://www.360view.vn/gallery/data/projects/vietnam/2015/hn9g/ ?0bclid=IwAR1eZ8F2COBm2KIgZC4OkcffmKOvWACUYSEiT 4KsXixIDXU3gMtge5Lzd58 [4] X. Zhu, X. Wang, J. Wang, P. Jin, L. Liu, and D. Mei, “Image super-resolution based on sparse representation via direction and edge dictionaries,” Mathematical Problems in Engineering, 2017. [5] C. Jiang, Q. Zhang, R. Fan, and Z. Hu, “Super-resolution CT image reconstruction based on dictionary learning and sparse representation,” Scientific Reports, 11 June 2018. [6] T. L. Tien and N. L. H. Sinh, “Performing image resolution super by the method of irregular data interpolation and filter bank,” The Minor Project on Superresolutions and Filter Banks (in Vietnamese), Ho Chi Minh University of Technology, Ho Chi Minh City, Vietnam, 2007. [7] T. Le Tien and D. V. Nguyen, “Super-resolution image processing combining transform between the frequency domain and wavelets domains (In Vietnamese),” Journal Research, Development and Application on Information & Communication Technology, pp. 39-47, April 2009. [8] W. Yang, X. Zhang, Y. Tian, W. Wang, J. Xue, and Q. Liao, “Deep learning for single image super-resolution: A brief review,” IEEE Signal Processing Magazine, 2019. [9] M. Kawulok, P. Benecki, S. Piechaczek, K. Hrynczenko, D. Kostrzewa, and J. Nalepu, “Deep learning for multiple-image super-resolution,” IEEE Signal Processing Magazine, 2019. [10] I. J. Goodfellow, et al., “Generative adversarial nets,” in Proc. Neural Information Processing Systems Conference, 2014. [11] C. Ledig, et al., “Photo-Realistic single image super-resolution using a generative adversarial network,” arXiv:1609.04802, 2017. [12] B. Wu, H. Duan, Z. Liu, and G. Sun, “SRPGAN: Perceptual generative adversarial network for single image,” arXiv:1712.05927, 2017. [13] Y. Zhang, Y. Tian, B. Zhong, and Y. Fu, “Residual dense network for image super-resolution,” arXiv:1802.08797, 2018. [14] X. Wang, et al., “ESRGAN: Enhanced super-resolution generative adversarial networks,” arXiv:1809.00219, 2018. [15] A. Jolicoeur-Martineau, and L. D. Institute, “The relativistic discriminator: A key element missing from standard GAN,” arXiv:1807.00734, 2018. [16] M. J. Islam, S. S. Enan, P. Luo, and J. Sattar, “Underwater image super-resolution using deep residual multipliers,” arXiv:1909.09437, 2019.
Copyright © 2020 by the authors. This is an open access article distributed under the Creative Commons Attribution License (CC BYNC-ND 4.0), which permits use, distribution and reproduction in any medium, provided that the article is properly cited, the use is noncommercial and no modifications or adaptations are made. 
Thuong Le-Tien (MIEEE-96) was born in Saigon, Ho Chi Minh City, Vietnam. He received the Bachelor and Master Degrees in Electronics-Engineering from Ho Chi Minh City Uni. of Technology (HCMUT), Vietnam, then the Ph.D. in Telecommunications from the Uni. of Tasmania, Australia. Since May 1981 he has been with the EEE Department at the HCMUT. He spent 3 years in the Federal Republic of Germany as a visiting scholar at
the Ruhr Uni. from 1989-1992. He served as Deputy Department Head for many years and had been the Telecommunications Department Head from 1998 until 2002. He had also appointed for the second position as the Director of Center for Overseas Studies since 1998 up to May 2010. His areas of specialization include: Communication Systems, Signal Processing and Electronic Circuits. He has published more than 180 scientific articles and the teaching materials for university students related to Electronic Circuits 1 and 2, Digital Signal Processing and Wavelets, Antenna and Wave Propagation, Communication Systems. Currently he is a full professor at the HCMUT. 
Tuan Nguyen-Thanh was born in Ho Chi Minh City, Vietnam. He received B.Eng. and M.Eng. degrees from Ho Chi Minh City University of Technology (HCMUT), Vietnam, in 2002 and 2004, respectively, both in electrical engineering and telecommunications. He has been at the HCMUT since 2002. Currently, he is pursuing the Ph.D. degree at the HCMUT. His main research interests include watermarking, digital signal processing and communication systems. 
Hanh Phan-Xuan got the B.Eng and M.Eng. Degrees from the Ho Chi Minh City University of Technology (HCMUT), Vietnam. His research relates to Image Signal Processing, Neural Networks and Deep Learning Techniques to solve problems in Computer Vision, Image Forgery Detection, Biometrics Signal Processing, and Autonomous Robotics. Currently, he is a Ph.D. Student at EEE Department of the HCMUT. 
Giang Nguyen-Truong was born in Tay Ninh, Vietnam. He got the Bachelor degree in 1999 with the Advanced Program of the Office for International Student Program (OISP) in Telecommunication major, Electrical and Electronics Engineering Department, Ho Chi Minh City University of Technology, HCMUT, Vietnam. His research related to apply machine learning to help solving inverse problem in image processing, particularly in Image Super Resolution.
Vinh Ta-Quoc was born in Binh Phuoc Province, Vietnam. He got the Bachelor degree in 1999 with the Advanced Program of the Office for International Student Program (OISP) in Telecommunication major, Electrical and Electronics Engineering Department, Ho Chi Minh City University of Technology (HCMUT), Viet Nam. His research related to apply machine learning to help solving inverse problem in image processing, particularly in Image Super - Resolution.
References (10)
- A. Lucas, M. Iliadis, R. Molina, and A. K. Katsaggelos, "Using deep neural networks for inverse problems in imaging," IEEE Signal Processing Magazine, January 2018.
- Z. Wang, J. Chen, S. C. H. Hoi, "Deep learning for image super- resolution: A survey," arXiv:1902.06068v2, Feb. 2020.
- Ha Noi 9 gigapixel. [Online]. Available: https://www.360view.vn/gallery/data/projects/vietnam/2015/hn9g/ ?fbclid=IwAR1eZ8F2COBm2KlgZC4OkcffmKOvWACUYSEiT 4KaXizIDXU3gMtge5LoJ58
- X. Zhu, X. Wang, J. Wang, P. Jin, L. Liu, and D. Mei, "Image super-resolution based on sparse representation via direction and edge dictionaries," Mathematical Problems in Engineering, 2017.
- C. Jiang, Q. Zhang, R. Fan, and Z. Hu, "Super-resolution CT image reconstruction based on dictionary learning and sparse representation," Scientific Reports, 11 June 2018.
- T. L. Tien and N. L. H. Sinh, "Performing image resolution super by the method of irregular data interpolation and filter bank," The Minor Project on Superresolutions and Filter Banks (in Vietnamese), Ho Chi Minh University of Technology, Ho Chi Minh City, Vietnam, 2007.
- T. Le Tien and D. V. Nguyen, "Super-resolution image processing combining transform between the frequency domain and wavelets domains (In Vietnamese)," Journal Research, Development and Application on Information & Communication Technology, pp. 39-47, April 2009.
- W. Yang, X. Zhang, Y. Tian, W. Wang, J. Xue, and Q. Liao, "Deep learning for single image super-resolution: A brief review," IEEE Signal Processing Magazine, 2019.
- M. Kawulok, P. Benecki, S. Piechaczek, K. Hrynczenko, D. Kostrzewa, and J. Nalepa, "Deep learning for multiple-image super-resolution," IEEE Signal Processing Magazine, 2019.
- I. J. Goodfellow, et al., "Generative adversarial nets," in Proc.
FAQs
AI
What efficiency do deep learning models achieve in single image super-resolution?addThe study shows that deep learning models outperform traditional methods with PSNR scores reaching 34.22 after training.
How does the Residual Dense Block architecture enhance image super-resolution?addThe architecture improves feature extraction through local and global feature fusion, leading to superior detail recovery.
What training dataset is primarily used for image super-resolution in this research?addThe DIV2K dataset, comprising approximately 800 high-quality images, is utilized for model training and validation.
What challenges exist in assessing image quality from super-resolution models?addMetrics like PSNR and SSIM often fail to align with human visual perception, complicating quality assessment.
How does incremental training influence the performance of super-resolution networks?addThe approach gradually increases resolution, improving model stability and enabling better detail recovery in generated images.
Related papers
Enhanced Super-Resolution Using GANIJRASET PublicationInternational Journal for Research in Applied Science & Engineering Technology (IJRASET), 2022
Super-resolution reconstruction is an increasingly important area in computer vision. To eliminate the problems that super-resolution reconstruction models based on generative adversarial networks are difficult to train and contain artifacts in reconstruction results. besides the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper convolutional neural networks. However, the hallucinated details are often accompanied with unpleasant artifacts. This paper presented ESRGAN model which was also based on generative adversarial networks. To further enhance the visual quality, we thoroughly study three key components of SRGAN-network architecture, adversarial loss and perceptual loss, and improve each of them to derive an Enhanced SRGAN (ESRGAN). In particular, we introduce the Residual-in-Residual Dense Block (RRDB) without batch normalization as the basic network building unit. Moreover, we borrow the idea from relativistic GAN to let the discriminator predict relative realness instead of the absolute value. Finally, we improve the perceptual loss by using the features before activation, which could provide stronger supervision for brightness consistency and texture recovery. Benefiting from these improvements, the proposed ESRGAN achieves consistently better visual quality with more realistic and natural textures than SRGAN.
downloadDownload free PDFView PDFchevron_rightDeep learning-based image super-resolution using generative adversarial networks with adaptive loss functionsTELKOMNIKA TeamTELKOMNIKA Telecommunication Computing Electronics and Control, 2025
This study investigates deep learning based single image super-resolution (SISR) and highlights its revolutionary potential. It emphasizes the significance of SISR, and the transition from interpolation to deep learningdriven reconstruction techniques. Generative adversarial network (GAN)based models, including super-resolution generative adversarial network (SRGAN), video super-resolution network (VSRResNet), and residual channel attention-generative adversarial network (RCA-GAN) are utilised. The proposed technique describes the loss functions of the SISR models. However, it should be noted that the conventional methods frequently fail to recover lost high-frequency details, which signify their limitations. The current visual inspections indicate that the suggested model can perform better than the others in terms of quantitative metrics and perceptual quality. The quantitative results indicate that the utilised model can achieve an average peak signal-to-noise ratio (PSNR) enhancement of X dB and an average structural similarity index (SSIM) increase of Y. A range of improvements of 7.12-23.21% and 2.75-10.00% are obtained for PSNR and SSIM, respectively. Also, the architecture deploys a total of 2,005,571 parameters, with 2,001,475 of these being trainable. These results highlight the model's efficacy in maintaining key structures and generating visually appealing outputs, supporting its potential implications in fields demanding high-resolution imagery, such as medical imaging and satellite imagery.
downloadDownload free PDFView PDFchevron_rightImage Super-Resolution using Generative Adversarial Networks with EfficientNetV2Taghreed JustiniaInternational Journal of Advanced Computer Science and Applications
The image super-resolution is utilized for the image transformation from low resolution to higher resolution to obtain more detailed information to identify the targets. The superresolution has potential applications in various domains, such as medical image processing, crime investigation, remote sensing, and other image-processing application domains. The goal of the super-resolution is to obtain the image with minimal mean square error with improved perceptual quality. Therefore, this study introduces the perceptual loss minimization technique through efficient learning criteria. The proposed image reconstruction technique uses the image super-resolution generative adversarial network (ISRGAN), in which the learning of the discriminator in the ISRGAN is performed using the EfficientNet-v2 to obtain a better image quality. The proposed ISRGAN with the EfficientNet-v2 achieved a minimal loss of 0.02, 0.1, and 0.015 at the generator, discriminator, and self-supervised learning, respectively, with a batch size of 32. The minimal mean square error and mean absolute error are 0.001025 and 0.00225, and the maximal peak signal-to-noise ratio and structural similarity index measure obtained are 45.56985 and 0.9997, respectively.
downloadDownload free PDFView PDFchevron_rightA Novel Image Super-Resolution Reconstruction Framework Using the AI Technique of Dual Generator Generative Adversarial Network (GAN)loveleen KumarJUCS - Journal of Universal Computer Science
Image superresolution (SR) is the process of enlarging and enhancing a low-resolution image. Image superresolution helps in industrial image enhancement, classification, detection, pattern recognition, surveillance, satellite imaging, medical diagnosis, image analytics, etc. It is of utmost importance to keep the features of the low-resolution image intact while enlarging and enhancing it. In this research paper, a framework is proposed that works in three phases and generates superresolution images while keeping low-resolution image features intact and reducing image blurring and artifacts. In the first phase, image enlargement is done, which enlarges the low-resolution image to the 2x/4x scale using two standard algorithms. The second phase enhances the image using an AI-empowered Generative adversarial network (GAN). We have used a GAN with dual generators and named it EffN-GAN (EfficientNet-GAN). Fusion is done in the last phase, wherein the final improved image is generated by ...
downloadDownload free PDFView PDFchevron_rightPhoto-Realistic Single Image Super-Resolution Using a Generative Adversarial NetworkKevin Ruiz VargasDespite the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper con-volutional neural networks, one central problem remains largely unsolved: how do we recover the finer texture details when we super-resolve at large upscaling factors? The behavior of optimization-based super-resolution methods is principally driven by the choice of the objective function. Recent work has largely focused on minimizing the mean squared reconstruction error. The resulting estimates have high peak signal-to-noise ratios, but they are often lacking high-frequency details and are perceptually unsatisfying in the sense that they fail to match the fidelity expected at the higher resolution. In this paper, we present SRGAN, a generative adversarial network (GAN) for image super-resolution (SR). To our knowledge, it is the first framework capable of inferring photo-realistic natural images for 4× upscaling factors. To achieve this, we propose a perceptual loss function which consists of an adversarial loss and a content loss. The adversarial loss pushes our solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images. In addition, we use a content loss motivated by perceptual similarity instead of similarity in pixel space. Our deep residual network is able to recover photo-realistic textures from heavily downsampled images on public benchmarks. An extensive mean-opinion-score (MOS) test shows hugely significant gains in perceptual quality using SRGAN. The MOS scores obtained with SRGAN are closer to those of the original high-resolution images than to those obtained with any state-of-the-art method.
downloadDownload free PDFView PDFchevron_rightImage Super-Resolution using DCNNMahesh Sachinist— We propose a deep leaning based approach due to the recent advances in technology. The deep learning based techniques have proved their edge over the state-of-the-art. We use end-to-end mapping on the low resolution and high resolution patches. We use Adam Algorithm for optimization with learning rate 0.0003 for all layers instead of classical stochastic gradient descent(SGD) procedure. It helped to attain best results fast. We take a low resolution image as an input and output is the high resolution image with better texture and edges representation.
downloadDownload free PDFView PDFchevron_rightBrain Mri Super Resolution Using Generative Adversarial Networkswalter primosichInternational conference on Medical Imaging with Deep Learning: Amsterdam, 4 - 6th July 2018, 2018
In this work we propose an adversarial learning approach to generate high resolution MRI scans from low resolution images. The architecture, based on the SRGAN model, adopts 3D convolutions to exploit volumetric information. For the discriminator, the adversarial loss uses least squares in order to stabilize the training. For the generator, the loss function is a combination of a least squares adversarial loss and a content term based on mean square error and image gradients in order to improve the quality of the generated images. We explore different solutions for the upsampling phase. We present promising results that improve classical interpolation, showing the potential of the approach for 3D medical imaging super-resolution.
downloadDownload free PDFView PDFchevron_rightImage Denoising and Super-Resolution using Residual Learning of Deep Convolutional NetworkRohit Pardasani2018
Image super-resolution and denoising are two important tasks in image processing that can lead to improvement in image quality. Image super-resolution is the task of mapping a low resolution image to a high resolution image whereas denoising is the task of learning a clean image from a noisy input. We propose and train a single deep learning network that we term as SuRDCNN (super-resolution and denoising convolutional neural network), to perform these two tasks simultaneously . Our model nearly replicates the architecture of existing state-of-the-art deep learning models for super-resolution and denoising. We use the proven strategy of residual learning, as supported by state-of-the-art networks in this domain. Our trained SuRDCNN is capable of super-resolving image in the presence of Gaussian noise, Poisson noise or any random combination of both of these noises.
downloadDownload free PDFView PDFchevron_rightFine-Grained Attention and Feature-Sharing Generative Adversarial Networks for Single Image Super-ResolutionXianfang SunIEEE Transactions on Multimedia, 2021
The traditional super-resolution methods that aim to minimize the mean square error usually produce the images with over-smoothed and blurry edges, due to the lose of highfrequency details. In this paper, we propose two novel techniques in the generative adversarial networks to produce photo-realistic images for image super-resolution. Firstly, instead of producing a single score to discriminate images between real and fake, we propose a variant, called Fine-grained Attention Generative Adversarial Network for image super-resolution (FASRGAN), to discriminate each pixel between real and fake. FASRGAN adopts a Unet-like network as the discriminator with two outputs: an image score and an image score map. The score map has the same spatial size as the HR/SR images, serving as the fine-grained attention to represent the degree of reconstruction difficulty for each pixel. Secondly, instead of using different networks for the generator and the discriminator in the SR problem, we use a feature-sharing network (Fs-SRGAN) for both the generator and the discriminator. By network sharing, certain information is shared between the generator and the discriminator, which in turn can improve the ability of producing high-quality images. Quantitative and visual comparisons with the state-ofthe-art methods on the benchmark datasets demonstrate the superiority of our methods. The application of super-resolution images to object recognition further proves that the proposed methods endow the power to reconstruction capabilities and the excellent super-resolution effects.
downloadDownload free PDFView PDFchevron_rightImage Super-Resolution Using Generative Adversarial Networks with Learned Degradation OperatorsMolefe Collymore MolefeMATEC web of conferences, 2022
Image super-resolution is a research endeavour that has gained notoriety in computer vision. The research goal is to increase the spatial dimensions of an image using corresponding low-resolution and highresolution image pairs to enhance the perceptual quality. The challenge of maintaining such perceptual quality lies in developing appropriate algorithms that learn to reconstruct higher-quality images from their lowerresolution counterparts. Recent methods employ deep learning algorithms to reconstruct textural details prevalent in low-resolution images. Since corresponding image pairs are non-trivial to collect, researchers attempt super-resolution by creating synthetic low-resolution representations of high-resolution images. Unfortunately, such methods employ ineffective downscaling operations to achieve synthetic low-resolution images. These methods fail to generalize well on real-world images that may suffer different degradations. A different angle is offered to solve the task of image super-resolution by investigating the plausibility of learning the degradational operation using generative adversarial networks. A two-stage generative adversarial network along with two architectural variations is proposed to solve the task of real-world super-resolution from lowresolution images with unknown degradations. It is demonstrated that learning to downsample images in a weakly supervised manner is an impactful and viable approach for super-resolution.
downloadDownload free PDFView PDFchevron_rightkeyboard_arrow_downView more papersRelated topics
- Explore
- Papers
- Topics
- Features
- Mentions
- Analytics
- PDF Packages
- Advanced Search
- Search Alerts
- Journals
- Academia.edu Journals
- My submissions
- Reviewer Hub
- Why publish with us
- Testimonials
- Company
- About
- Careers
- Press
- Help Center
- Terms
- Privacy
- Copyright
- Content Policy
Từ khóa » Hà Nội 9 Gigapixel
-
Hanoi 9 Gigapixel
-
HÀ NỘI 9 GIGAPIXEL NHA... - Chiếc Bàn Của Tôi | Facebook
-
Hà Nội Cũng Có ảnh 9 Tỷ Pixel Siêu Nét Zoom Từng Viên ... - ICTNEWS
-
Hà Nội Cũng Có ảnh 9 Tỷ Pixel Siêu Nét Zoom Từng Viên Gạch, Và đây ...
-
Quang Cảnh Hà Nội Trong Bức ảnh 12 Gigapixel - VnExpress Số Hóa
-
Khám Phá Ngay 84 Triệu Ngôi Sao Qua Hình ảnh 9 Gigapixel Của Dải ...
-
Hành Trình Nhiếp ảnh Của Những Người đi 'săn' Chân Trời - Hà Nội 9 ...
-
Việt Nam Cũng Có ảnh Siêu Khủng Với 13 Tỷ Pixel, Chụp Tại Hà Nội, Huế
-
Topaz Gigapixel AI
-
UNIS HA NOI 360°
-
Hà Nội Cũng Có ảnh độ Phân Giải Tỷ Pixel Soi Rõ Từng Gương Mặt ...
-
Golden Jungle House
-
Hướng Dẫn Check-in Xếp Xe Kỷ Lục Hình Bản đồ Việt Nam Và Chụp ...