Độ Phức Tạp Của Thuật Toán - Big O Notation Trong Lập Trình
Có thể bạn quan tâm
Bạn có thể đã từng nghe câu hỏi này từ ai đó, hoặc từ chính bản thân mình: “liệu có thể làm tốt công việc của một software developer nếu không biết đến Độ phức tạp của thuật toán, hay Big O Notation? “, đặc biệt là khi bạn làm ở những vị trí như front end developer. Chắc chắn bạn vẫn làm được công việc của mình mà không cần nắm rõ khái niệm này.
Tuy nhiên, điều gì sẽ xảy ra khi bạn làm việc với một tập hợp với hàng trăm nghìn đến hàng trăm triệu element? Hay thậm chí lên đến hàng tỷ phần tử? Và đặc biệt khi phải tính đến khả năng mở rộng của một hệ thống? Khi đó Big O Notation hay Độ phức tạp của thuật toán trở nên quan trọng.
Vậy Độ phức tạp của thuật toán là gì? Đó là một khái niệm khá trừu tượng mà nhiều người không nghe đến hoặc ít quan tâm đến nó. Nhưng hiểu được nó sẽ giúp bạn rất nhiều trong công việc và cũng không kém quan trọng, khái niệm này được biết đến như là một câu hỏi phỏng vấn về lập trình mà các nhà tuyển dụng luôn muốn nghe câu trả lời đúng của bạn.
Big O Notation là gì?
Big-O notation là ngôn ngữ chúng ta sử dụng để nói về thời gian một thuật toán thực thi (độ phức tạp về thời gian – time complexity) hoặc bao nhiêu bộ nhớ được sử dụng bởi một thuật toán (độ phức tạp không gian – space complexity). Big-O notation có thể thể hiện thời gian chạy tối ưu nhất, chậm nhất và trung bình của một thuật toán. Trong bài viế này chúng ta sẽ tập trung chủ yếu vào time complexity, tức độ phức tạp về thời gian.
Là một kỹ sư phần mềm, bạn sẽ thấy rằng hầu hết các cuộc thảo luận về Big-O đều tập trung vào thời gian chạy “giới hạn trên” của một thuật toán, thường được gọi là trường hợp xấu nhất. Một phần quan trọng cần lưu ý là “thời gian chạy” khi sử dụng Big-O notation không trực tiếp tương đương với thời gian như chúng ta biết (ví dụ: giây, mili giây, micro giây, v.v.). Phân tích thời gian chạy không tính đến những thứ nhất định, chẳng hạn như bộ xử lý, ngôn ngữ hoặc môi trường thời gian chạy. Thay vào đó, chúng ta có thể coi thời gian là số phép tính hoặc số bước cần thực hiện để hoàn thành một bài toán cỡ n. Nói cách khác, ký hiệu Big-O là một cách để theo dõi thời gian chạy (runtime) phát triển nhanh như thế nào so với kích thước của đầu vào (input).
Khi chúng ta nghĩ về trường hợp xấu nhất, câu hỏi trở thành – những phép tính / bước nào có thể xảy ra nhất đối với đầu vào có kích thước n?
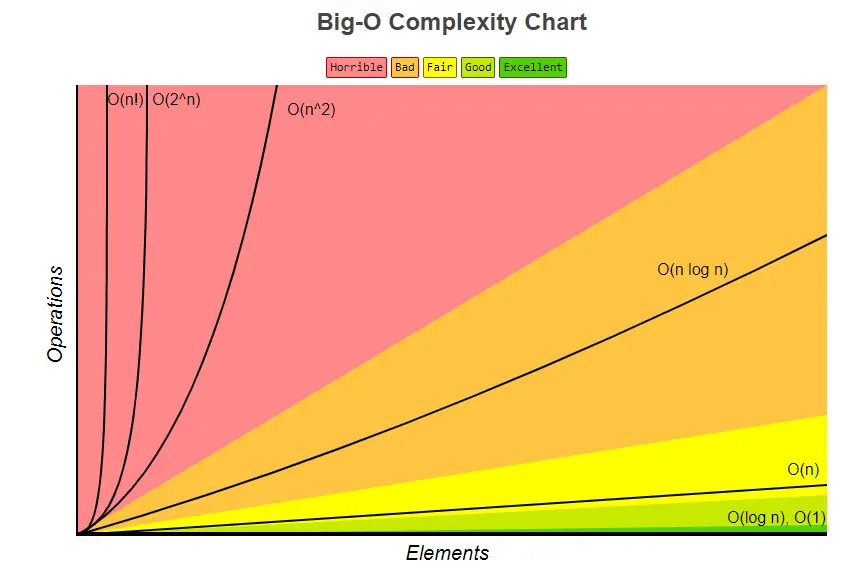
Trong biểu đồ trên, trục Y được gắn nhãn Operations và trục X được gắn nhãn là Elements. Elements đề cập đến số lượng đầu vào trong khi Operations đề cập đến số lượng phép tính được sử dụng để xử lý số lượng đầu vào nói trên. Có bảy mức độ phức tạp về thời gian khác nhau với tên gọi riêng và chúng ta sẽ đi qua các khái niệm này.
Những mức độ phức tạp của Big O
O (1) → Thời gian là hằng số
O (1) có nghĩa là cần một thời gian không đổi để chạy một thuật toán, bất kể kích thước của đầu vào.
Bookmark (đánh dấu trang) là một ví dụ tuyệt vời về thời gian không đổi sẽ diễn ra như thế nào trong thế giới thực. Đánh dấu trang cho phép người đọc tìm thấy trang cuối cùng mà bạn đã đọc một cách nhanh chóng và hiệu quả. Không khác nhau nếu bạn đang đọc một cuốn sách có 30 trang hay một cuốn sách có 1000 trang. Miễn là bạn đang sử dụng bookmark, bạn sẽ tìm thấy trang cuối cùng đó trong một bước duy nhất.
Trong lập trình, rất nhiều thao tác là hằng số. Dưới đây là một số ví dụ:
- phép toán
- truy cập một mảng thông qua chỉ mục
- truy cập hàm băm thông qua khóa
- push và pop trên một ngăn xếp
- chèn và xóa khỏi hàng đợi
- trả về một giá trị từ một hàm
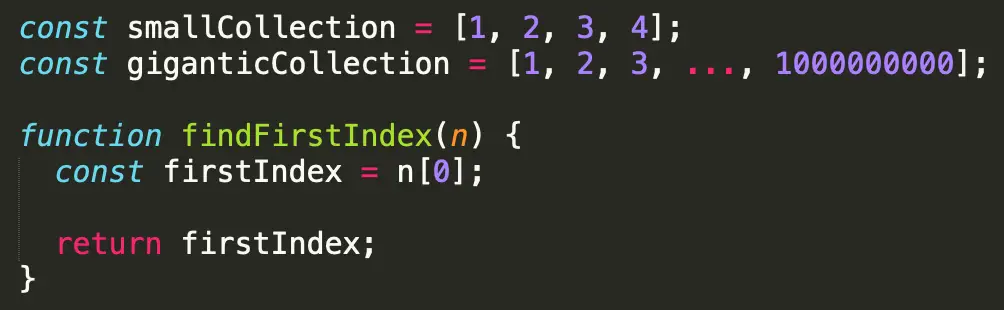
Hãy xem findFirstIndex, được liệt kê bên dưới. Truyền smallCollection hoặc giganticCollection sẽ tạo ra cùng một thời gian chạy của O (1) khi truy cập chỉ mục 0. Trả về của firstIndex cũng là một hoạt động theo thời gian không đổi. Bất kể kích thước của n, cả hai hoạt động này sẽ mất một khoảng thời gian không đổi.
O (n) → thời gian tuyến tính
O (n) có nghĩa là thời gian chạy tăng cùng tốc độ với đầu vào.
Hành động đọc sách là một ví dụ về thời gian tuyến tính (linear) sẽ diễn ra như thế nào trong thế giới thực. Giả sử rằng ta mất đúng 1 phút để đọc một trang của một cuốn sách in khổ lớn. Cho rằng, một cuốn sách có 30 trang, tôi sẽ mất 30 phút để đọc. Tương tự như vậy, một cuốn sách có 1000 trang = 1000 phút đọc. Chúng ta có thể không buộc mình phải hoàn thành những cuốn sách không hay – vì vậy, luôn có khả năng tôi sẽ không đọc hết cuốn sách 1.000 trang đó. Tuy nhiên, trước khi bắt đầu đọc, tôi có thể biết rằng thời gian đọc trong trường hợp tệ nhất của tôi là 1000 phút cho một cuốn sách 1000 trang.
Trong lập trình, một trong những phép toán thời gian tuyến tính phổ biến nhất là duyệt qua một mảng. Trong JavaScript, các phương thức như forEach, map và Reduce chạy xuyên suốt toàn bộ bộ sưu tập dữ liệu, từ đầu đến cuối.
Hãy xem hàm printAllValues của chúng ta bên dưới. Số phép toán mà nó sẽ thực hiện để lặp qua n liên quan trực tiếp đến kích thước của n. Nói chung (nhưng không phải lúc nào cũng vậy), việc nhìn thấy một vòng lặp là một dấu hiệu cho thấy đoạn mã cụ thể mà bạn đang kiểm tra có thời gian chạy là O (n).

Nhưng những gì về phương pháp tìm thấy? Vì nó không phải lúc nào cũng chạy qua toàn bộ collection, nó có thực sự là tuyến tính không? Trong ví dụ dưới đây, giá trị đầu tiên nhỏ hơn 3 nằm ở chỉ mục 0 của tập hợp. Tại sao đây không phải là thời gian cố định?
Hãy nhớ rằng – vì chúng ta đang tìm kiếm trường hợp xấu nhất, chúng ta phải giả định rằng đầu vào sẽ không phải là lý tưởng và phần tử hoặc giá trị mà chúng ta tìm kiếm có thể là giá trị cuối cùng trong mảng. Trong tình huống thứ hai (bên dưới), bạn sẽ thấy điều đó. Tìm số nhỏ hơn ba, trong trường hợp ít lý tưởng nhất, sẽ yêu cầu lặp lại toàn bộ mảng.

O (n²) → Thời gian bậc hai
O (n²) có nghĩa là phép tính chạy theo thời gian bậc hai (quadratic), là kích thước bình phương của dữ liệu đầu vào.
Trong lập trình, nhiều thuật toán sắp xếp cơ bản hơn có thời gian chạy trong trường hợp xấu nhất là O (n²):
- Bubble Sort
- Insertion Sort
- Selection Sort
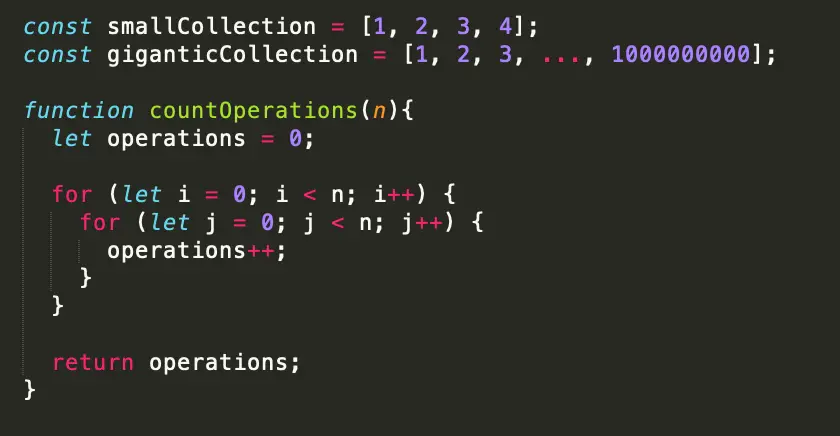
Hãy xem hàm countOperations bên dưới. Ở đây chúng ta có hai vòng lặp lồng nhau đang tăng biến hoạt động sau mỗi lần lặp. Nếu n là smallCollection , chúng ta sẽ kết thúc với số lượng 16 phép toán. Khá nhỏ. Nhưng nếu n là giganticCollection của chúng ta thì sao? Một tỷ lần một tỷ là ngàn tỷ tỷ tỷ (1030) – hoặc 1.000.000.000.000.000.000.000. Rất, rất nhiều. Ngay cả một mảng có ít nhất 1.000 phần tử cũng sẽ tạo ra một triệu phép toán.
Nói chung (nhưng không phải lúc nào cũng vậy), việc nhìn thấy hai vòng lặp lồng nhau thường là một tín hiệu cho thấy đoạn code bạn đang xem có thời gian chạy là O (n²). Tương tự như vậy – ba vòng lặp lồng nhau sẽ cho biết thời gian chạy là O (n³).
O (log n) → Thời gian logarit (Logarithmic Time)
O (log n) có nghĩa là thời gian chạy tăng tương ứng với logarit của kích thước đầu vào, có nghĩa là thời gian chạy hầu như không tăng khi bạn tăng đầu vào theo cấp số nhân.
Tìm một từ trong từ điển vật lý bằng cách giảm một nửa kích thước mẫu là một ví dụ tuyệt vời về cách hoạt động của thời gian logarit trong thế giới thực. Ví dụ: khi tìm từ “senior”, bạn có thể mở từ điển một cách chính xác ở giữa – tại thời điểm đó bạn có thể xác định xem những từ bắt đầu bằng “s” đứng trước hay sau những từ mà ban hiện đang xem. Khi bạn xác định rằng “s” nằm ở nửa sau của cuốn sách, bạn có thể loại bỏ tất cả các trang trong nửa đầu. Sau đó bạn lặp lại quá trình tương tự. Bằng cách làm theo thuật toán này đến cùng, bạn sẽ cắt giảm 1/2 số trang tôi phải tìm kiếm mỗi lần cho đến khi tôi tìm thấy từ đó.
Trong lập trình, hành động tìm kiếm trong từ điển vật lý này là một ví dụ của thao tác tìm kiếm nhị phân – đây là ví dụ điển hình nhất được sử dụng khi thảo luận về thời gian chạy của lôgarit (logarithmic runtimes)
Hãy xem phiên bản sửa đổi của hàm countOperations của. Lưu ý rằng n bây giờ là một số: n có thể là một đầu vào (số) hoặc kích thước của một đầu vào (độ dài của một mảng).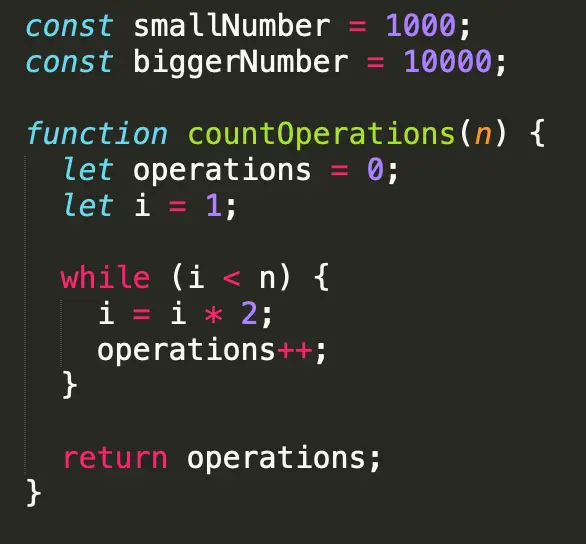
Trong ví dụ của chúng tôi ở trên, chúng ta kết thúc với 11 phép toán nếu n = 2000. Nếu n = 4.000, chúng tôi kết thúc với 12 phép toán. Mỗi khi chúng ta tăng gấp đôi số lượng n, số lượng phép toán chỉ tăng thêm 1. Các thuật toán chạy theo thời gian logarit có ý nghĩa lớn khi nói đến các đầu vào lớn hơn. Sử dụng ví dụ trẹn, O (log (7)) sẽ trả về ba phép toán. Một O (log (1000000)) sẽ chỉ trả về 20 phép toán.
O (n log n) → Thời gian chạy tuyến tính với logarit
O(n log n), thường bị nhầm lẫn với O (log n), có nghĩa là thời gian chạy của một thuật toán là tuyến tính, là sự kết hợp của độ phức tạp tuyến tính và logarit.
Các thuật toán sắp xếp sử dụng chiến lược chia để trị có độ phức tạp dạng linearithmic này, chẳng hạn như sau:
- merge sort
- timsort
- heapsort
Khi xem xét độ phức tạp thời gian, O (n log n) nằm giữa O (n2) và O (n).
Tính toán độ phức tạp của thuật toán
Cho đến lúc này, chúng ta chỉ tập trung vào việc nói về Big-O bằng cách cô lập một vài dòng mã tại một thời điểm. Làm cách nào để tính toán Big-O nếu chúng ta đang xử lý một thuật toán có nhiều phần?
Bỏ các hằng số (constants)
Hãy bắt đầu với logEverythingTwice.
Vì Big-O quan tâm đến việc thời gian chạy của chúng ta phát triển nhanh như thế nào, nên quy tắc đầu tiên bạn muốn nhớ là bỏ bất kỳ hằng số nào khi bạn phân tích một thuật toán.
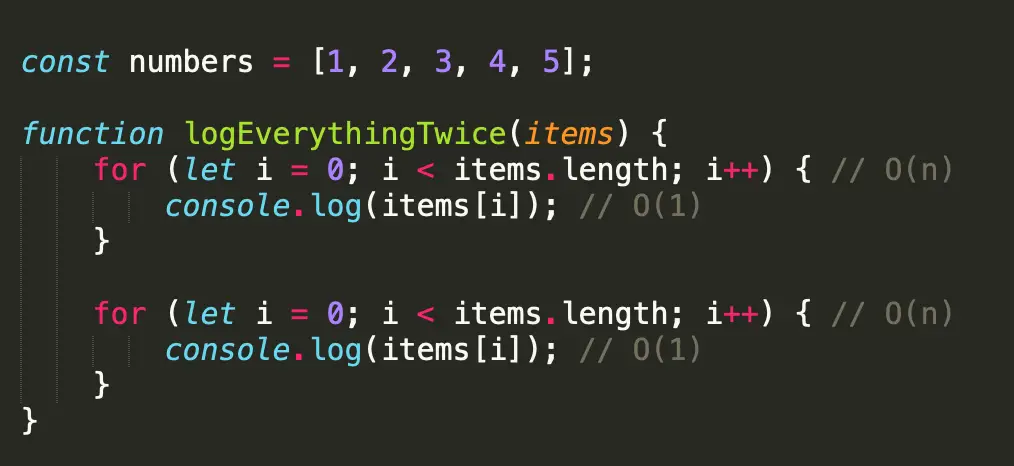
Trong ví dụ trên, chúng ta có hai vòng lặp riêng biệt đang lặp qua độ dài của một mảng (tuyến tính). Mỗi vòng lặp ghi lại một mục trong collection (hằng số). Vì chúng ta không quan tâm đến các phép tính chạy trong thời gian không đổi (chúng tạo ra sự khác biệt nhỏ trong ước tính tổng thể), chúng ta sẽ chỉ tính đến hai vòng lặp và cộng chúng lại với nhau và cho chúng ta kết quả O (2n). Vì số hai cũng là một hằng số trong trường hợp này, chúng ta loại bỏ nó và gọi nó là O (n).
Nhưng điều gì sẽ xảy ra nếu những vòng lặp này được lồng vào nhau?
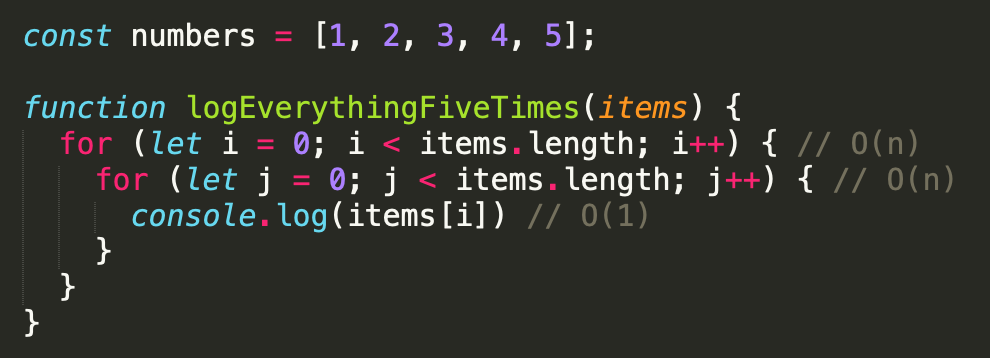
Với việc lồng các vòng lặp này, chúng ta không còn ghi lại các items[i] hai lần nữa – mà là năm lần! Trong trường hợp này, chúng ta nhân O (n) * O (n) thay vì cộng số lần chạy với nhau. Chúng ta làm điều này bởi vì việc thực thi nhật log của chúng ta phụ thuộc vào việc lặp lại toàn bộ vòng lặp thứ hai (ghi lại i năm lần) trước khi chúng ta có thể tăng i và chuyển sang index tiếp theo thông qua vòng lặp đầu tiên. Đây là những gì log của chúng ta kết thúc trả về:
111112222233….
Cũng giống như ví dụ đầu tiên, chúng tôi vẫn muốn loại bỏ các hằng số khỏi các logs. Cuối cùng, O (n * n) cho chúng ta O (n²).
Bài học ở đây là bạn luôn tránh các vòng lặp lồng nhau do ảnh hưởng của hiệu suất. Bạn chắc chắn sẽ gặp phải những tình huống phải dùng giải pháp như vậy (tập dữ liệu nhỏ, thao tác với mảng đa chiều, v.v.). Tuy nhiên, bạn nên biết rằng có thể có những tác động về hiệu suất, tùy thuộc vào những gì bạn đang làm.
Bỏ các điều khoản không chiếm ưu thế
Hãy xem một ví dụ khác.
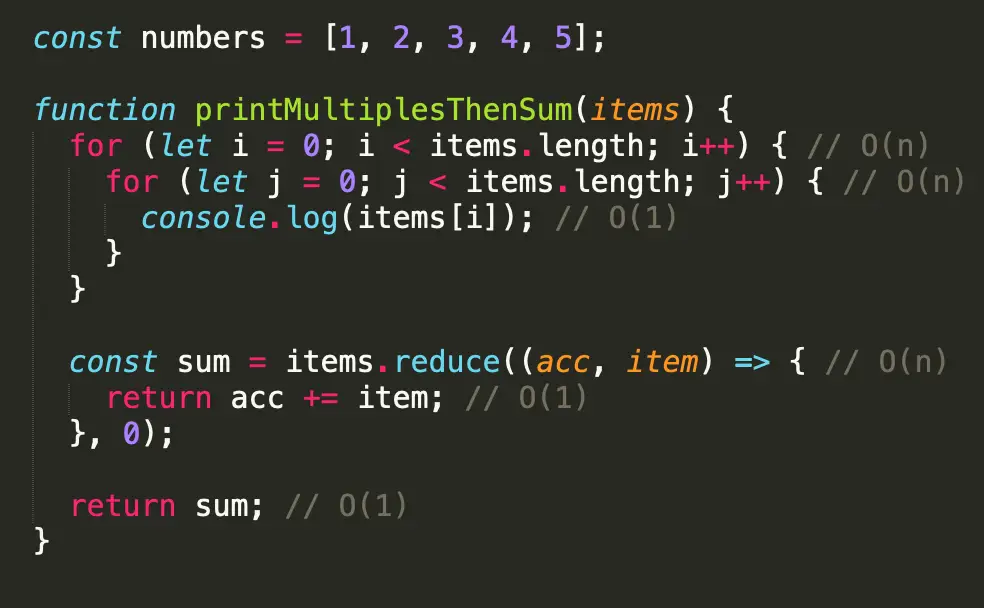
Sau khi loại bỏ các hằng số trong printMultiplesThenSum, chúng ta có thể thấy rằng Big-O notation cho hàm này sẽ là O (n² + n). Vì Big-O cũng không liên quan đến các số hạng không chiếm ưu thế, chúng ta bỏ n (thắng bậc hai vì nó tệ hơn thời gian tuyến tính). Loại bỏ các thuật ngữ không chiếm ưu thế là quy tắc thứ hai cần tuân theo khi phân tích thời gian chạy của một thuật toán. Cuối cùng, O (n² + n) cho chúng ta O (n²).
Tại sao bạn cần biết về độ phức tạp của thuật toán?
Sau khi đã tìm hiểu các khái niệm trên, bạn dã biết tại sao các công ty lại hỏi bạn về Big-O notation trong một cuộc phỏng vấn?
Câu trả lời là việc nghiên cứu độ phức tạp của thuật toán giúp bạn nắm bắt được khái niệm rất quan trọng về hiệu quả trong code của bạn. Khi bạn làm việc với các tập dữ liệu khổng lồ, bạn sẽ hiểu rõ nơi nào có khả năng gây ra tắc nghẽn lớn và nơi nào cần chú ý nhiều hơn để có được những cải tiến lớn nhất. Đây còn được gọi là phân tích độ nhạy (sensitivity analysis), và là một phần quan trọng trong việc giải quyết vấn đề và viết phần mềm một cách tối ưu nhất.
Vì vậy, nếu bạn đang chuẩn bị cho cuộc phỏng vấn về lập trình, thì việc nâng cao kiến thức về các khái niệm như Big O notation và các chủ đề khoa học máy tính khác sẽ giúp bạn tự tin hơn. Bạn sẽ được trang bị tốt hơn để thể hiện khả của mình và gây ấn tượng đối với nhà tuyển dụng.
Xem thêm các bài về phỏng vấn lập trình trên ITguru
- 140+ nguồn tài liệu để chuẩn bị cho phỏng vấn về lập trình
- 100+ câu hỏi phỏng vấn Java cùng hướng dẫn trả lời
- 50 câu hỏi phỏng vấn về giải thuật và cấu trúc dữ liệu dành cho lập trình viên
Tài liệu cho bài viết này:
- https://www.bigocheatsheet.com/
- Big-O Notation: A simple explanation with examples
- 8 time complexities that every programmer should know
Bạn đánh giá bài viết thế nào?
Submit RatingAverage rating 4.8 / 5. Vote count: 12
No votes so far! Be the first to rate this post.
Tags: Big O NotationĐộ phức tạp của giải thuậtĐộ phức tạp của thuật toánkỹ năng lập trình viênlập trình viênphỏng vấn developerphỏng vấn ngành CNTTTừ khóa » Tính độ Phức Tạp Thuật Toán Sắp Xếp
-
Độ Phức Tạp Của Thuật Toán Và Lựa Chọn Cách Giải Thuật
-
XÁC ĐỊNH ĐỘ PHỨC TẠP THUẬT TOÁN - Lập Trình
-
Độ Phức Tạp Tính Toán - VNOI
-
Thuật Toán Sắp Xếp Nào Là Nhanh Nhất? - Viblo
-
Tính độ Phức Tạp Của Một Số Thuật Toán Cơ Bản (Phần 2) - YouTube
-
Độ Phức Tạp Của Các Thuật Toán Sắp Xếp - Code Lean
-
Big O: Cách Tính độ Phức Tạp Của Thời Gian Và Không Gian - Code Lean
-
[Thuật Toán]Cách Tính độ Phức Tạp Thuật Toán - Algorithm Complexity
-
2.Đánh Giá độ Phức Tạp Của Giải Thuật Sắp Xếp Bằng Phương Pháp ...
-
Độ Phức Tạp Của Thuật Toán - Time Complexity - Yêu Lập Trình
-
Cách đánh Giá độ Phức Tạp Của Thuật Toán - .vn
-
[PDF] Bài 1 Thuật Toán đánh Giá Và Tiếp Cận - FIT@MTA
-
Thuật Toán Cơ Bản: Phân Tích độ Phức Tạp Giải Thuật | Hai Sam's Blog
-
[PDF] Giới Thiệu Các Thuật Toán Sắp Xếp