EDA With Python Library - Viblo
Có thể bạn quan tâm
Intro
Như mọi người cũng đã biết khi làm việc với dữ liệu thì việc phân tích, so sánh, biểu diễn mối tương quan giữa chúng cũng rất mất thời gian. Đặc biệt với lượng dữ liệu nhận được ngày càng lớn như hiện nay. Vì thế việc sử dụng các thư viện hỗ trợ có tác động rất lớn tới hiệu quả năng suất làm việc của mọi người. Chính vì thế trong bài viết này mình sẽ sử dụng một vài thư viện hay ho của Python hỗ trợ cho việc phân tích dữ liệu. Nếu các bạn biết các lib khác thì hãy chia sẻ thêm cho mọi người cùng biết nhé.
Ngoài ra các bạn có thể đọc thêm các bài viết về EDA tại đây :
- EDA dữ liệu cuộc thi Bookingchallenge và Baseline model - Pham Thi Hong Anh
- A Tutorial on EDA and Feature Engineering - Tran Duc Tan
- Data Visualize Cheatsheet for EDA - Nguyen Thanh Trung
Library
1.Sweetviz
Lib này khi gen kết quả trông cũng khá đẹp mắt, trông cũng xịn sò.Để sử dụng được Lib này đơn giản ta chỉ cần pip install Sweetviz.
pip install sweetvizXong. Để dùng thử thì mình sẽ dùng Data Supermarket_sales, các bạn có thể down tại đây.
Đầu tiên mình sẽ đọc thử data bằng Pandas thông thường mình hay dùng.
import pandas as pd df = pd.read_csv('Advertising.csv')Tiếp đến là ta sẽ dùng thằng Sweetviz xem thế nào. Cụ thể trong Sweetviz có hàm Analyze() sẽ show ra một trang HTML.
# importing sweetviz import sweetviz as sv #analyzing the dataset advert_report = sv.analyze(df) #display the report advert_report.show_html('Supermarket_sales.html')Kết quả nhận được như hình dưới đây :

Ta có thể quan sát thấy được có rất nhiều thông tin được đưa ra, nhìn vào từng biểu đồ có thể thấy rất trực quan, dễ hiểu. 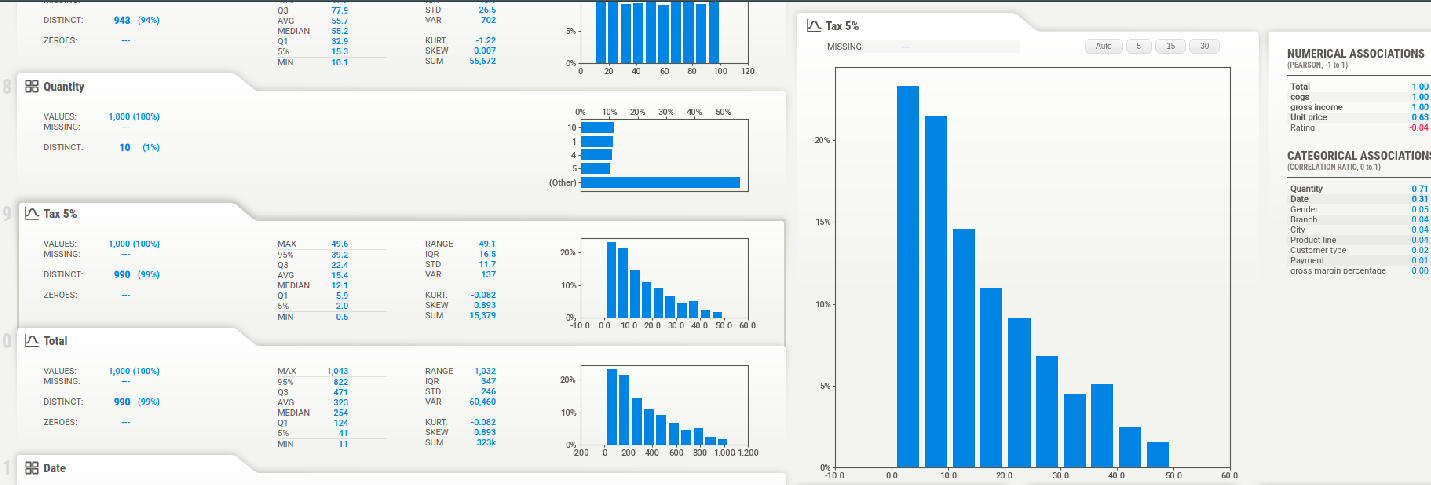
Không những thế, Lib này cũng hỗ trợ việc so sánh giá trị với nhau. Ví dụ như sau :
df1 = sv.compare(df[100:], df[:100]) df1.show_html('Compare.html')Kết quả nhận được như sau:

Ngoài ra còn có rất nhiều thứ hay ho của nó nữa, các bạn có thể xem thêm ở đây.
2.Pandas-Profiling
Tiếp theo là dùng Pandas-Profiling, một open-source python cho việc EDA data đơn giản. Về cài đặt thì cũng đơn giản. Mọi người cũng xem thêm code tại repo sau :
pip install pandas-profilingDone env . Việc sử dụng cũng không khó khăn gì mấy. Dữ liệu thì các bạn có thể tải tại đây để dùng thử (không thì dùng luôn data bên trên cũng được cho tiện).
import pandas as pd from pandas_profiling import ProfileReport #EDA using pandas-profiling profile = ProfileReport(pd.read_csv('titanic.csv'), explorative=True) #Saving results to a HTML file profile.to_file("output.html")Kết quả như dưới đây :

3. Autoviz
Tiếp đến là thư viện Autoviz. Việc cài đặt và sử dụng cũng vô cùng đơn giản.
pip install autovizVề dữ liệu demo thì mình vẫn dùng dữ liệu cũ (bên trên nhé). Code thự hiện việc phân tích data thì như sau :
import pandas as pd from autoviz.AutoViz_Class import AutoViz_Class #EDA using Autoviz autoviz = AutoViz_Class().AutoViz('supermarket_sales.csv')Kết quả thay vì gen ra trang HTML trên local thì nó sẽ gen trực tiếp luôn. 

4. Pandas
Khi nhắc đến EDA thì không thể thiếu Pandas được, một lib thần thánh cho việc visualize data. Trong pandas ta sẽ làm việc thường xuyên với funtion plot. Ngoài ra có các hàm thường sử dụng như pandas.DataFrame.groupby(), pandas.DataFrame.qcut() hay pandas.DataFrame.apply(),....
Hàm cơ bản thiếp theo là describe(), hàm này sẽ thống kê toàn bộ tỉ lệ giá trị có trong table bao gồm: mean, count, min, max, 25%, 75%, ...
data.describe()
Tiếp đến là Histogram. Hàm này sẽ thống kê giá trị của một column, số lượng có trong cột.
data[['Quantity']].plot.hist(bins = 20, title = 'Purchases Quantity Distribution')
Thêm style cho việc plot data thì có hàm style.background_gradient. Cụ thể như sau :
corr = data[['Quantity','UnitPrice','UnitDiscount','UnitWeight']].corr() corr.style.background_gradient(cmap='coolwarm').set_precision(2)Kết quả đươc như sau:

Cái thú vị nữa của Pandas là hỗ trợ vẽ biểu đồ. Nhìn vào nó sẽ cho ta biết sự thay đổi, phân bố của lượng data.
data['TransactionDiscount'] = data['Quantity'] * data['UnitDiscount'] #sum groupby InvoiceMonth df_monthly_discount = data[['InvoiceMonth','TransactionDiscount']].groupby('InvoiceMonth').sum() df_monthly_discount.reset_index(inplace = True) ax = df_monthly_discount.plot.line(x = 'InvoiceMonth', y = 'TransactionDiscount', color = 'lime') df_monthly_revenue.plot.line(x = 'InvoiceMonth', y = 'TransactionRevenue', color = 'salmon', title = 'Monthly Transaction Revenue and Discount', ax = ax)Và bùng. Kết quả là :

Trong thực tế khi nhìn vào biểu đồ thì sẽ xuất hiện thêm biểu đồ hình tròn hay Pie Chart và Pandas cũng có thể vẽ được biểu đồ như thế.
df_quarterly_revenue = df_monthly_revenue.groupby(df_monthly_revenue.index // 3).sum() df_quarterly_revenue.index = ['Q1','Q2','Q3','Q4'] df_quarterly_revenue.plot.pie(y = 'TransactionRevenue', title = 'Quarterly Revenue')Show Pie Chart kết quả như sau :

Ngoài ra thằng pandas này còn rất nhiều điều thú vị nữa, các bạn có thể xem thêm tại đây. Tạm thời mình viết đến đây, giới thiệu môt vài lib cơ bản, các bạn có thể thử, giúp cho việc phân tích data, đưa ra các cách xử lý phù hợp với task, nhiệm vụ của bài toán mình gặp. Bye bye !!!!
Refer
- https://pypi.org/project/sweetviz/
- https://github.com/pandas-profiling/pandas-profiling
Từ khóa » Thư Viện Lib Trong Python
-
Beginner Cần Biết: Top 30 Thư Viện Python Tốt Nhất (Phần 1)
-
TOP THƯ VIỆN PYTHON TỐT NHẤT - Hybrid Technologies
-
20 Thư Viện Python Bạn Không Thể Sống Thiếu Chúng - Techmaster
-
Tạo Gói Thư Viện Chuẩn Python - Minh Nguyen
-
[Python Cơ Bản] Cách Import Library Trong Python - YouTube
-
Thư Viện Chuẩn Python - Tech Wiki
-
Thư Viện Python: Cái Nào Tốt Nhất Cho Vai Trò Gì? - BitDegree
-
Thư Viện Python: Cái Nào Tốt Nhất Cho Vai Trò Gì? | TopDev
-
Cách Cài Thư Viện Thường Dùng Trong Python Trên Windows
-
Cách Cài đặt Thư Viện Python - Viblo
-
Cách Viết, Đóng Gói Và Phân Phối Một Thư Viện Trong Python
-
5 Thư Viện Python Hữu Ích Cho Các Dự Án Machine Learning 2022
-
20 Thư Viện Python Thông Dụng - HocTrucTuyen123.NET
-
Top Các Thư Viện Python Sử Dụng Cho Lập Trình Trí Tuệ Nhân Tạo - Blog