Gán Nhãn Từ Loại (Part-of-Speech Tagging POS) - Ông Xuân Hồng
Có thể bạn quan tâm

Trong nhiều tác vụ của Xử lý ngôn ngữ tự nhiên (XLNNTN), ta mong muốn xây dựng được một mô hình mà chuỗi các quan sát đầu vào (từ, ngữ, câu,…) đi kèm với chuỗi các nhãn đầu ra (từ loại, ranh giới ngữ, tên thực thể,…) gọi là pairs of sequences.
Gán nhãn từ loại (Part-of-speech tagging – POS) có lẽ là bài toán sớm nhất được nghiên cứu và được mọi người biết đến khi nhập môn chuyên ngành XLNNTN. Trong bài viết này, ta sẽ tìm hiểu về bài toán gán nhãn từ loại, các hướng tiếp cận và thuật toán cơ bản để giải quyết vấn đề này.
Giới thiệu
Trong gán nhãn từ loại, mục tiêu của chúng ta khi đưa chuỗi đầu vào là một câu ví dụ như “con ruồi đậu mâm xôi đậu”

thì chuỗi đầu ra sẽ là nhãn (tag sequence) được giống hàng tương ứng

Ở đây, D: determinator (định từ), N: noun (danh từ), V: verb (động từ). Khi đó, ta có chuỗi các cặp từ và từ loại tương ứng như sau

Gán nhãn (sequence labeling problem, tagging problem) có các bài toán thường gặp
- POS tagging (gán nhãn từ loại). Là cơ sở phục vụ cho các bài toán về ngữ nghĩa cao hơn.
- Named-Entity recognition (gán nhãn tên thực thể). Ví dụ: bà ba [CON NGUOI] bán bánh mì [THUC PHAM] ở phường mười ba [DIA DIEM]. Có giá trị về mặt ngữ nghĩa ở mức trung bình, thường được dùng để phân lớp văn bản.
- Machine translation (dịch máy). Đầu vào là một câu của ngôn ngữ A, đầu ra là câu của ngôn ngữ B tương ứng. Bài toán này từng rất cấp thiết trong chiến tranh thế giới thứ 2, khi mà thông tin tình báo của địch cần được dịch trong thời gian ngắn nhất, giúp cho các lãnh đạo có thể đưa ra những chiến lược cấp thiết.
- Speech recognition (nhận diện tiếng nói). Đầu vào là âm thanh tiếng nói, đầu ra là câu dạng văn bản. Ngày nay, theo thống kê của Apple, người dùng thích sử dụng tiếng nói của mình để nhập văn bản hơn là cách nhập dữ liệu bằng bàn phím như truyền thống, đồng thời tương tác giữa người và máy theo cách này có tốc độ nhập liệu nhanh hơn.
Khi làm việc với bài toán này ta sẽ đối mặt với hai thách thức chính
- Nhập nhằng (ambiguity): một từ có thể có nhiều từ loại, hay một từ có thể có nhiều nghĩa, Ví dụ “con ruồi đậu mâm xôi đậu“, từ “đậu” có lúc là động từ (hành động đậu lên một vật thể) hoặc có lúc là danh từ (tên của một loài thực vật).
- Trong thực tế, có nhiều từ không xuất hiện trong ngữ liệu huấn luyện (training corpus) nên khi xây dựng mô hình gán nhãn sẽ gặp nhiều khó khăn.
Độ chính xác của mô hình gán nhãn phụ thuộc vào hai yếu tố
- Bản thân từ đó sẽ có xu hướng (xác suất lớn) về từ loại nào. Ví dụ từ “đậu” có xu hướng là động từ nhiều hơn là danh từ (phụ thuộc vào ngữ liệu đang xét).
- Ngữ cảnh trong câu. Ví dụ “con ruồi đậu mâm xôi đậu“. Từ “đậu” có xu hướng là động từ khi theo sau từ “ruồi” và từ “đậu” có xu hướng là danh từ khi theo sau từ “xôi”.
Generative Models, và The Noisy Channel Model
Để gán nhãn từ loại, ta sử dụng phương pháp học có giám sát (supervised learning), cụ thể là xác suất liên hợp thường gọi là mô hình sinh mẫu (Generative model). Hidden Markov Model là một trong những mô hình thuộc phân nhóm này.
Supervised learning được định nghĩa như sau
Cho tập huấn luyện 




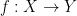


Để tính hàm
Sau khi huấn luyện các tham số của mô hình. Ta cho dữ liệu đầu vào là

Một hướng tiếp cận khác là generative model, thay vì tính trực tiếp hàm 

Hàm này được phân tích thành
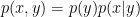
Trong đó
là phân bố xác suất tiền nghiệm (prior probability distribution) của nhãn
.
là khả năng phát sinh
Khi cho dữ liệu test đầu vào

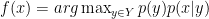
Quá trình phân tích ra
Generative Tagging Model
Định nghĩa: giả sử ta có tập từ vựng 


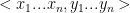



- Với mọi


- Và

Ta xây dựng ánh xạ từ câu 


Để xây dựng được hàm này ta cần trả lời các câu hỏi sau:
- Làm sao tính được
?
- Ước lượng tham số cho mô hình như thế nào từ ngữ liệu huấn luyện?
- Làm sao tính được xác suất cực đại
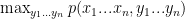
Trigram Hidden Markov Models (Trigram HMMs)
Ở câu hỏi đầu tiên, ta sẽ dùng trigram hidden Markov model. Mô hình này có hai tham số quan trọng là 

- Với mọi trigram
, ta có
, và
.
ngay sau bigram nhãn
.
- Với mọi
.
Với 

Lưu ý, ta đặt

Ví dụ câu “em ăn cơm”

Đây là một ví dụ cho mô hình noisy-channel với

là xác suất tiền nghiệm nhìn thấy chuỗi nhãn 

là xác suất có điều kiện của 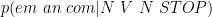

Ước lượng tham số cho mô hình Trigram HMM
Trả lời cho câu hỏi thứ hai, ta sẽ ước lượng tham số của mô hình bằng phương pháp maximum-likelihood cho hai tham số
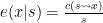
Trong đó
là số lần xuất hiện trigram
trong ngữ liệu huấn luyện.
là số lần xuất hiện bigram
trong ngữ liệu huấn luyện.
Ví dụ ta ước lượng
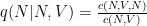
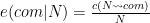
Trong trường hợp ta muốn “làm trơn” tham số để giải quyết vấn đề xuất hiện từ hiếm gặp, ta có thể thêm vào các thông số 

Trong đó, 

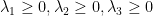
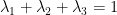
Decoding HMMs bằng thuật toán Viterbi
Giả sử ta có câu đầu vào là
em ăn cơm
với tập các từ loại 
N N N STOP N N V STOP N V V STOP V V V STOP …
Như vậy, đối với câu gồm 3 từ, ta sẽ có tất cả 
Ý tưởng thuật toán Viterbi
Thay vì tính toán hết các trường hợp, ta có thể áp dụng phương pháp quy hoạch động (dynamic programming) như thuật toán Viterbi với
Đầu vào:
Đầu ra: 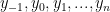


Xác suất có điều kiện của 
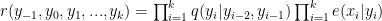
Như vậy công thức 

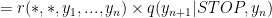
Đặt 


Tiếp theo, với mọi 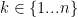






Trong đó, 
Phần cơ sở
Phần đệ quy
Với mọi
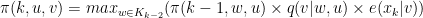
Như vậy, ta đã trả lời được câu hỏi thứ ba

Độ phức tạp tính toán của thuật toán này là 

Tiếp theo, ta sẽ mô tả bằng ngôn ngữ mã giả bằng hai thuật toán: thuật toán đệ quy cơ bản và thuật toán đệ quy có con trỏ lần ngược (để xác định chuỗi nhãn đang xét có xác suất là bao nhiêu).
Thuật toán đệ quy cơ bản
Input: a sentence 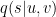
Definitions: Define 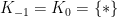


Initialization: Set 
Algorithm:
- For
- For
- For
- Return
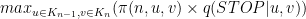
Thuật toán đệ quy có backward pointer
Input: a sentence
Definitions: Define
Initialization: Set
Algorithm:
- For
- For
- For
- Set
- For
,
- Return the tag sequence
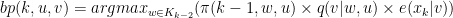


Kết
Như vậy, ta đã tìm hiểu được thế nào là bài toán gán nhãn từ loại, các hướng tiếp cận và thuật toán để giải quyết vấn đề này. Một số điểm cần nhớ
- Trigram HMM có hai tham số quan trọng là
, với
.
- Khi cho trước ngữ liệu huấn luyện, ta có thể ước lượng maximum-likelihood cho hai tham số trên


- Khi cho một câu test đầu vào
được ước lượng trong quá trình huấn luyện, ta có thể xác định được xác suất cực đại của chuỗi nhãn
Nguồn tham khảo
- Tagging Problems, and Hidden Markov Models
- Gán nhãn từ loại tiếng Việt dựa trên các phương pháp học máy thống kê
- JVnTagger: Công cụ gán nhãn từ loại tiếng Việt dựa trên Conditional Random Fields và Maximum Entropy
- Gán nhãn từ loạI cho tiếng việt dựa trên văn phong và tính toán xác suất
- Gán nhãn từ loạI tiếng việt sử dụng mô hình markov ẩn
- Sử dụng bộ gán nhãn từ loạI xác suất qtag cho văn bản tiếng việt
Có liên quan
Từ khóa » Gán Nhãn Từ Loại
-
[PDF] Gán Nhãn Từ Loại Tiếng Việt Dựa Trên
-
Gán Nhãn Từ Loại – Wikipedia Tiếng Việt
-
[PDF] Gán Nhãn Từ Loại
-
[PDF] Nghiên Cứu Gán Nhãn Từ Loại Cho Văn Bản Tiếng Việt Bằng Phương ...
-
[PDF] Gán Nhãn Từ Loại Tiếng Việt Sử Dụng Mô Hình Markov ẩn
-
[PDF] VẤN ĐỀ GÁN NHÃN TỪ LOẠI CHO VĂN BẢN TIẾNG VIỆT - Vietlex
-
GÁN NHÃN TỪ LOẠI - MP.BPO Hàng đầu Tại Việt Nam
-
TÌM HIỂU Bài TOÁN Gán NHÃN Từ LOẠI (POS TAGGING) - Tài Liệu Text
-
API NLP – Part-of-Speech Tagging (Gán Nhãn Từ Loại) - Viettel AI
-
[PDF] GÁN NHÃN TỪ LOẠI CHO TIẾNG VIỆT DỰA TRÊN VĂN PHONG ...
-
Gán Nhãn Từ Loại Cho Tiếng Việt Dựa Trên Văn Phong Và Tính Toán Xác ...
-
Gán Nhãn Từ Loại Tiếng Việt Dựa Trên Các Phương Pháp Học Máy ...
-
Gán Nhãn Từ Loại - Wiki Tiếng Việt - Du Học Trung Quốc
-
18520339/vietnamese-pos-tagging: Gán Nhãn Từ Loại Tiếng Việt Sử ...