Kafka Connect - Free As A Bird. It's The Next Best Thing To Be….
Có thể bạn quan tâm
Kafka Connect là một framework cho phép stream data in/out tới Apache Kafka. Confluent Platform cung cấp sẵn một số connectors có thể dùng để stream data in/out tới 1 số hệ thống như hệ quản trị cơ sở dữ liệu quan hệ (MySQL, Oracle…) hoặc HDFS.
JDBC connector trong Kafka Connect cho phép lấy dữ liệu (source) từ cơ sở dữ liệu đẩy vào Kafka topic và đẩy dữ liệu (sink) từ Kafka topic tới cơ sở dữ liệu. Nó hỗ trợ toàn bộ các hệ quản trị cơ sở dữ liệu có implement JDBC driver như Oracle, SQL Server, DB2, MySQL, Postgres…
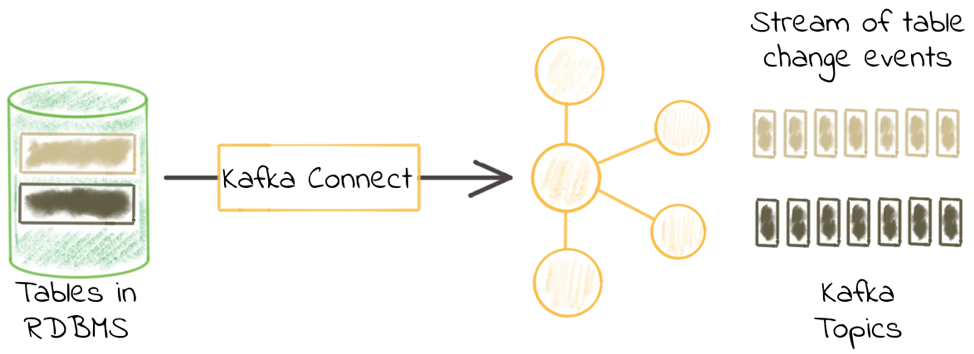
Một số khái niệm cơ bản trong Kafka Connector:
Connectors định nghĩa nguồn hoặc đích đến của dữ liệu. Một connector instance chịu trách nhiệm sao chép dữ liệu giữa Kafka và hệ thống khác. Toàn bộ classses implement hoặc sử dụng bơi connector đều được định nghĩa trong connector plugin.
Confluent Platform đã cung cấp sẵn khá nhiều Source Connector. Ví dụ: JDBC, AWS S3, HDFS… Tuy nhiên nếu cần chúng ta vẫn có thể viết thêm các connector mới. Flow cơ bản thì như hình bên dưới đây:

Về cơ bản chúng ta sẽ cần implement 2 interface là Connector và Task.
Class implement Connector sẽ chịu trách nhiệm về nguồn dữ liệu cần trích xuất còn classs implement Task chịu trách nhiệm đọc dữ liệu từ nguồn sau đó tạo các bản ghi dữ liệu để đẩy vào topic của Kafka.
Task là thành phần chính trong kiến trúc của Connector. Mỗi connector instance điều phối một nhóm các task thực thi việc đọc dữ liệu từ nguồn chỉ định. (JDBC, S3…). Bằng việc cho phép chia nhỏ job thành nhiều task, Kafka Connect cung cấp sẵn khả năng xử lý song song và mở rộng việc đọc dữ liệu thông qua cầu hình. Để làm được việc này thì trạng thái của Task được lưu trong Kafka topic là: config.storage.topic và status.storage.topic và quản lý bởi connector. Do vậy mà task có thể khởi động, tạm dừng hoặc khởi động lại bất kỳ lúc nào.
Task Rebalancing khi một connector tham gia vào cụm, những worker sẽ tự động reblance toàn bộ connector trong cụm và những task của connector đó, mục đích để đảm bão mỗi worker sẽ đảm nhận số lượng công việc giống nhau. Quá trình reblancing này cũng diễn ra khi một connecto tăng hoặc giảm số lượng task hoặc khi connector cập nhật lại cấu hình. Khi một worker chết, task sẽ tự động rebalance với những worker đang hoạt động. Trái lại một task nếu chết sẽ bị coi là trường hợp ngoại lệ, do vậy task sẽ không tự động khởi động lại mà cần được khởi động lại thông qua REST API.

Workers Connectors và task những phần việc sẽ được lập lịch để thực thi trong 1 tiến trình. Một tiến trình khi khởi chạy sẽ được gọi là 1 worker. Có 2 chế độ cho phép lựa chọn khi start worker là Standalone và Distributed.
Standalone
Distributed cung cấp khả năng mở dộng và tự động và khả năng chịu lỗi (auto failover) cho Kafka Connect. Trong mode distributed, chúng ta có thể chạy nhiều worker với chung group.id, tất cả các worker đang hoạt động sẽ tự động phối hợp cùng nhau lên lịch thực hiện task.
Converters chịu trách nhiệm chuyển đổi định dạng dữ liệu từ dạng byte sang định dạng quy định trong Connector. VD: Json, Protobuf…

Transforms
Dead Letter Queue
Chia sẻ:
- X
Từ khóa » Kafka Connect Là Gì
-
010: Apache Kafka Connect Concept - Viblo
-
Sự Ra đời Của Kafka Connect | Facebook
-
Kafka Connect - Phần 1: Getting Started | Facebook
-
Cách Sử Dụng Kafka Connect Trên Heroku để Kết Nối Hai Nguồn Dữ Liệu
-
Kafka Là Gì? Ứng Dụng Kafka Cơ Bản Cho Hệ Thống Message | TopDev
-
Hướng Dẫn Cài đặt Và ứng Dụng Kafka Connect - VTS Engineering
-
Kafka Connect | Tuyen Nguyen
-
Connect Là Gì Cụm Từ Kafka Connect Là Gì - Bình Dương
-
Ứng Dụng Của Kafka Và Kafka Connect Trong Xây Dựng Kiến Trúc ...
-
Kafka Connect - Confluent Documentation
-
Kafka Là Gì Cụm Từ Kafka Stream Là Gì - Bình Dương
-
Apache Kafka Là Gì? Tất Cả Mọi Thứ Bạn Cần Biết - VSUDO Blog
-
Apache Kafka được Quản Lý Hoàn Toàn – Amazon MSK