Nhận Dạng ảnh Cơ Bản Với Python - Viblo
Có thể bạn quan tâm
Tổng quan
Ngày nay, xử lý ảnh đang là một lĩnh vực mà rất nhiều người quan tâm, nghiên cứu. Nhờ vào sự phát triển mạnh mẽ của Machine Learning - một lĩnh vực nhỏ của Khoa Học Máy Tính, nó có khả năng tự học hỏi dựa trên dữ liệu đưa vào mà không cần phải được lập trình cụ thể, xử lý ảnh đã và đang được ứng dụng vào nhiều lĩnh vực trong cuộc sống: y tế (X Ray Imaging, PET scan,...), thị giác máy tính (giúp máy tính có thể hiểu, nhận biết đồ vật như con người), các cộng nghệ nhận dạng (vân tay, khuôn mặt,..),... Trong bài viết này, mình sẽ giới thiệu đến các bạn một chương trình nhận dạng đơn giản với mong muốn giúp cho mọi người hiểu rõ hơn về ứng dụng của xử lý ảnh cũng như Machine Learning.
Các bước cơ bản của quá trình nhận dạng ảnh
Bước 1: Chuẩn bị tập dữ liệu và rút trích đặc trưng
Đây là công đoạn được xem là quan trọng nhất trong các bài toán về Machine Learning. Vì dữ liệu này được dùng cho quá trình học để tìm ra mô hình của bài toán. Nếu chúng ta xây dựng được một mô hình tốt thì kết quả sẽ cho độ chính xác cao hơn, vì vậy cần phải chọn ra được những đặc trưng tốt của dữ liệu, và loại bỏ những đặc trưng không tốt, gây nhiễu ở dữ liệu.
Bước 2: Xây dựng mô hình
Mục đích của mô hình huấn luyện là tìm ra hàm f(x), thông qua nó dán nhãn cho dữ liệu. Bước này thường được gọi là học hay training. Thông thường để xây dựng mô hình phân lớp cho bài toán này, chúng ta sử dụng các thuật toán học giám sát như KNN, Neural Network, SVM, Decision Tree, Navie Bayers,Random Forest...
Bước 3: Đánh giá mô hình
Ở bước này chúng ta sẽ đánh giá mô hình bằng cách đánh giá độ chính xác của dữ liệu test thông qua mô hình vừa xây dựng. Nếu không đạt được kết quả mong muốn của chúng ta thì phải thay đổi các tham số của các thuật toán học để tìm ra các mô hình tốt hơn và kiểm tra, đánh giá lại mô hình. Và cuối cùng chọn ra mô hình phân lớp cho bài toán đã đưa ra.
Bài toán phân loại trái cây dựa vào hình ảnh
Chuẩn bị dữ liệu:
Dữ liệu train và test được lấy từ đây. Trong chương trình này, mình chỉ sử dụng 18 loại trái cây dưới đây. 
Xác định bộ mô tả hình ảnh
Như đã nói ở trên, bước đầu tiên của quá trình nhận dạng ảnh đó là xây dựng được các bộ mô tả hình ảnh (để trích xuất ra được đặc trưng quan trọng của dữ liệu). Để có thể xây dựng được một bộ mô tả hình ảnh phù hợp, chúng ta cần xác định rõ đặc điểm nào của các bức ảnh sẽ được sử dụng để phân biệt chúng, có thể là màu sắc chủ đạo, hình dạng của đối tượng trong bức ảnh, kết cấu, hoa văn hoặc là kết hợp các đặc điểm này lại. Ở đây chúng ta phân tích 1 bức ảnh dựa trên 3 chỉ số: 1, Color histogram (màu sắc) Color histogram là một dạng đặc trung toàn cục biểu diễn phân phối của các màu trên ảnh. Color histogram thống kê số lượng các pixel có giá trị nằm trong một khoảng màu nhất định cho trước. Color histogram có thể tính trên các dạng ảnh RGB hoặc HSV, thông dụng là HSV (Hue – vùng màu, Saturation – độ bão hòa màu, Value – độ sáng). Cài đặt trên Python:
def fd_histogram(image, mask=None): # chuyển về không gian màu HSV image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) hist = cv2.calcHist([image], [0, 1, 2], None, [bins, bins, bins], [0, 256, 0, 256, 0, 256]) # normalize histogram cv2.normalize(hist, hist) return hist.flatten()2, Hu Monents (hình dạng) Hu Monents là một Image Descriptor sử dụng các phép thống kê để mô tả hình dạng của một đối tượng có trong bức ảnh nhị phân hoặc edged-image. Hu Moments Image Descriptor trả về một Feature Vector gồm 7 giá trị. Feature Vector này sẽ được so sánh với nhau để xác định sự tương đồng giữa hai vật thể. Cài đặt trên Python:
def fd_hu_moments(image): # chuyển về ảnh gray image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) feature = cv2.HuMoments(cv2.moments(image)).flatten() return feature3, Haralick Texture (kết cấu – hoa văn) Haralick được dùng để mô tả kết cấu (texture) và hoa văn (pattern) của một bức ảnh, đối tượng, bao gồm vẻ bề ngoài (appearance), sự nhất quán (consistency) và cảm giác về bề mặt (“feeling of surface”) có trong bức ảnh. Cài đặt trên Python:
def fd_haralick(image): # chuyển về ảnh gray gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) haralick = mahotas.features.haralick(gray).mean(axis=0) return haralickChương trình huấn luyện
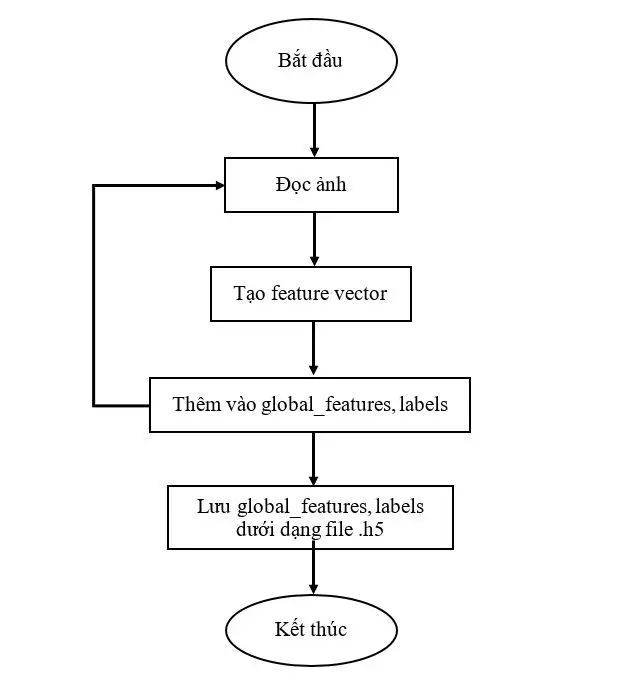
Chương trình đánh giá
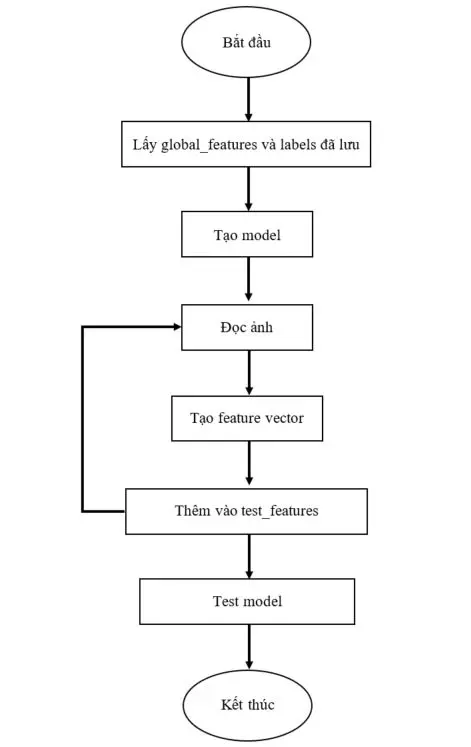
Kết luận
Hi vọng qua chương trình trên mọi người có thể nắm được một trong những ứng dụng của xử lý ảnh cũng như Machine Learning.
Tài liệu tham khảo
Bài viết có tham khảo từ các nguồn sau đây: Image Classification using Python and Scikit-learn Color Channel Statistics and Color Histograms Hu Moments Haralick Texture Features
Từ khóa » Thuật Toán Xử Lý ảnh Trong Python
-
Xử Lý Hình ảnh Trong Python: Từ Thuật Toán đến Công Cụ - VinBigData
-
Xử Lý Ảnh Cơ Bản Với OpenCV Trong Python (P1) - CodeLearn
-
Convolution - Xử Lý ảnh Qua Ví Dụ Python Thực Tế - Techmaster
-
Xử Lý Hình ảnh Bằng Python - Koodibar
-
Bài Tập Xử Lý ảnh Có Lời Gải – Code Python ( OpenCV )
-
Tách Biên ảnh Trong Bài Toán Nhận Dạng Người Và Vật Thể - YouTube
-
Xử Lý ảnh Với OpenCV Python - Bài 4 - YouTube
-
Tìm Hiểu Xử Lý ảnh Bằng OpenCV Trong Python - Thực Hành 2
-
Xử Lý ảnh Với Opencv-python Cơ Bản ( Phần 1/n) - Hóng Tin
-
Xử Lý ảnh - OpenCV đọc Ghi Hình ảnh (code Python Và C++)
-
Bài 21 - Tiền Xử Lý ảnh OpenCV
-
Detect Ký Tự Trong Hình ảnh - Viblo
-
Lập Trình OpenCV - THỊ GIÁC MÁY TÍNH
-
Xử Lý ảnh Với Python Và Opencv - Tài Liệu Text - 123doc