Xử Lý Ngôn Ngữ Tự Nhiên Với Python - P4 - Viblo
Có thể bạn quan tâm
Ở phần này, chúng ta sẽ đi tìm hiểu một chút về xác vấn đề và xử lý xoay quanh Python Lists, mà cụ thể ở đây là Lists các Token, Sentence hay Word. Đây là một công việc cơ bản cần làm khi xử lý ngôn ngữ với Python. Các giá trị đầu vào, các Dataset hay văn bản thường được đưa về dạng Lists, hay Dict của Python để xử lý dễ dàng hơn. Ngoài ra, chúng ta sẽ cũng tìm hiểu về một số kiến thức cơ bản về thống kê và ứng dụng của chúng trong việc xử lý ngôn ngữ. Các kiến thức ở đây đều rất cơ bản và không có gì phức tạp cả.
1. Lists of WordsỞ bài trước, ta đã biết cách sử dụng các văn bản mẫu bằng cách Import package Book của NLTK. Bằng việc gọi các text từ 1-9, ta gọi lần lượt văn bản của toàn bộ các cuốn sách.
Danh sách
NLTK Book ngoài cung cấp các văn bản text từ 1-9, nó còn cung cấp cho chúng ta các sentence, tức là các câu. Ở đây, ta thử lấy ra nội dung 1 câu mà NLTK Book cung cấp, bắt đầu với "sent1".
>>> sent1 ['Call', 'me', 'Ishmael', '.']Ta thấy "sent1" được cung cấp dưới dạng 1 Python lists, chứa các từ và dấu câu của 1 sentence. Và vì nó là 1 list, cho nên ta có thể đếm số từ và dấu câu mà nó chứa.
>>> len(sent1) 4Bây giờ hãy thử tạo 1 List các từ của 1 câu do bạn nghĩ ra. Ở đây tôi có câu "Donald Trump is president 45th of USA". Kết quả như sau:
>>> my_sent = ["Donald", "Trump", "is", "president", "45th", "of","USA"] >>> len(my_sent) 7 >>> sorted(set(my_sent)) ['45th', 'Donald', 'Trump', 'USA', 'is', 'of', 'president'] >>> my_sent.count("is") 1Vì nó là 1 list, cho nên tôi có thể cộng nó với 1 list khác, ở đây là "sent1" ở trên.
>>> my_sent + sent1 ['Donald', 'Trump', 'is', 'president', '45th', 'of', 'USA', 'Call', 'me', 'Ishmael', '.']Hay là thêm phần từ cho nó
>>> my_sent.append("America") >>> my_sent ['Donald', 'Trump', 'is', 'president', '45th', 'of', 'USA', 'America']Index của Lists
Vì các text của Book cũng là List cho nên ta có thể truy cập tới từng phần từ thông qua index (key).
>>> text4[1005] 'Heaven'Ta cũng có thể truy lộn lại bằng cách sử dụng phần tử, bằng hàm index()
>>> text4.index("Heaven") 1005Hoặc bạn muốn lấy từ các trong một khoảng index nào đó (slicing)
>>> text5[16715:16735] ['U86', 'thats', 'why', 'something', 'like', 'gamefly', 'is', 'so', 'good', 'because', 'you', 'can', 'actually', 'play', 'a', 'full', 'game', 'without', 'buying', 'it']Bây giờ cùng thử với my_sent mà tôi đã tạo ở trên.
>>> my_sent ['Donald', 'Trump', 'is', 'president', '45th', 'of', 'USA', 'America'] >>> my_sent[0] 'Donald' >>> my_sent[6] 'USA' >>> my_sent.index("Trump") 1 >>> my_sent.index("of") 5Trong Python list thì index có rất nhiều cách truy cập. Ở đây tôi chỉ liệt kê 2 cách cơ bản là index và slicing. Bạn hãy tìm hiểu thêm nhé.
Strings
String căn bản cũng có các tính chất tương tự như một Lists. Tôi lấy ví dụ một string chứa câu "Donald Trump is president 45th of USA".
>>> my_str = "Donald Trump is president 45th of US" >>> my_str[5] 'd' >>> my_str.index("i") 13 >>> my_str + " and very rich" 'Donald Trump is president 45th of US and very rich' >>> my_str * 2 'Donald Trump is president 45th of USDonald Trump is president 45th of US' 2. Thống kê căn bản.Chúng ta bắt đầu nghiên cứu một số phương pháp thống kê căn bản và áp dụng nó vào Xử lý ngôn ngữ.
Frequency Distributions - Phân bố theo tần suất.
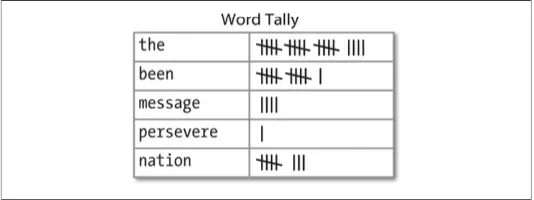 Ảnh trên là một ví dụ về bẳng phân bố theo tần suất. Theo đó, ta liệt kê danh sách các từ và số lần xuất hiện của chúng trong văn bẳn thành 2 cột. Ví dụ từ "the" xuất hiện 19 lần, trong khi từ "message" chỉ xuất hiện 4 lần. NLTK cung cấp cho chúng ta 1 hàm để tính phân bố tần suất, đó là FreqDist(). Ta có ví dụ: Tìm ra 50 từ có tần suất xuất hiện nhiều nhất trong văn bản text1.
Ảnh trên là một ví dụ về bẳng phân bố theo tần suất. Theo đó, ta liệt kê danh sách các từ và số lần xuất hiện của chúng trong văn bẳn thành 2 cột. Ví dụ từ "the" xuất hiện 19 lần, trong khi từ "message" chỉ xuất hiện 4 lần. NLTK cung cấp cho chúng ta 1 hàm để tính phân bố tần suất, đó là FreqDist(). Ta có ví dụ: Tìm ra 50 từ có tần suất xuất hiện nhiều nhất trong văn bản text1.
Một lưu ý nhỏ là để lấy Key của Dict trong Python 3, ta phải convert nó sang dạng List để truy cập được bằng Indexing. Và trước khi thực hiện gọi gàm FreqDist(), bạn phải đảm bảo mình đã import NLTK Book nhé.
Bây giờ chúng ta sẽ cùng Visualize kết quả 1 chút nhé. NLTK có tích hợp thêm buổi đồ cho chúng ta bằng việc sử dụng Matplotlib, hiện tại thì bạn chưa cần quan tâm xem nó là gì cả, chỉ cần thử để ra kết quả thôi. Đầu tiên là ta xem biểu đồ về tần xuất của 50 từ được dùng nhiều nhất trong văn bản text1.
fdist1 = FreqDist(text1) fdist1.plot(50)Kết quả 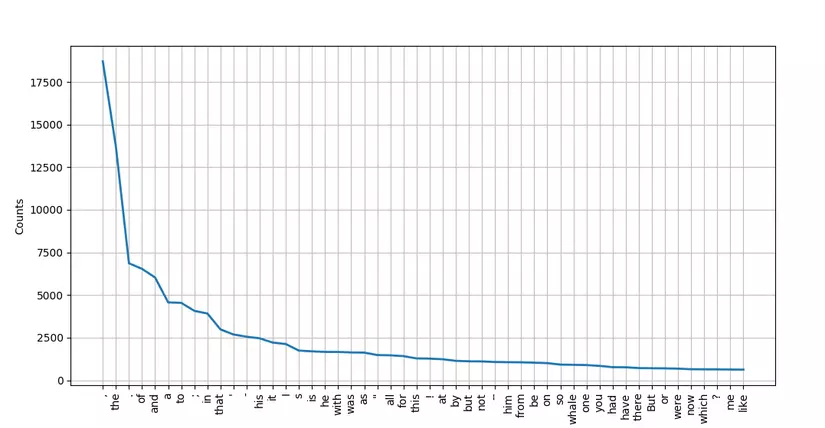 Ta thấy từ "the" được sử dụng nhiều nhất, lên tới trên 17 ngàn lần xuất hiện. Từ like xuât hiện ít nhất trong 50 từ này, cũng rơi vào khoảng vài trăm lần. Tiếp theo ta thử tính tổng số lần xuất hiện của 50 từ trên và biểu diễn chúng trên biểu đồ nhé. Param có tên "cumulative" cho phép chúng ta tính tổng luỹ tích của các từ, đơn giản ta chỉ cần set nó là True.
Ta thấy từ "the" được sử dụng nhiều nhất, lên tới trên 17 ngàn lần xuất hiện. Từ like xuât hiện ít nhất trong 50 từ này, cũng rơi vào khoảng vài trăm lần. Tiếp theo ta thử tính tổng số lần xuất hiện của 50 từ trên và biểu diễn chúng trên biểu đồ nhé. Param có tên "cumulative" cho phép chúng ta tính tổng luỹ tích của các từ, đơn giản ta chỉ cần set nó là True.
Kết quả 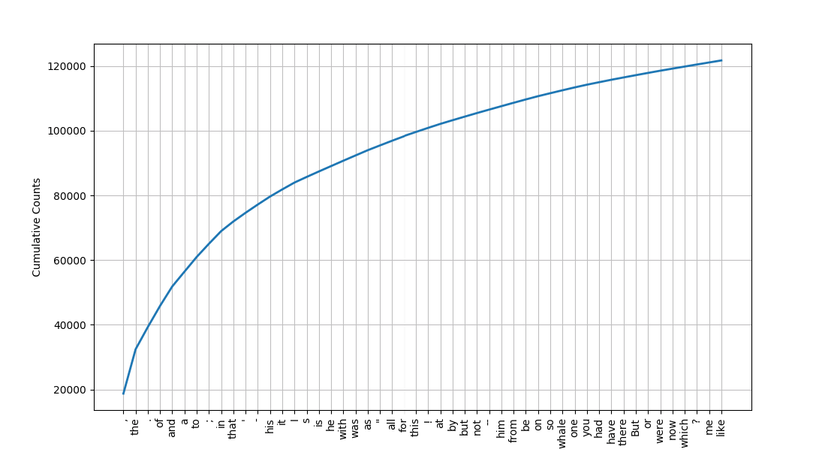 Vậy là 50 từ này xuất hiện tổng cộng hơn 120 ngàn lần trong văn bản. Bằng cách lấy len() của text1, ta thấy 50 từ chiếm phân nửa số từ trong văn bẳn text1. Bạn có thể sử dụng phương pháp tính phân bố theo tần xuất này để xác định các từ được sử dụng nhiều trong các bài báo, bài viết hay các Status trên mạng xã hội để xem từ nào đang là Trend nhé. Một ví dụ nữa mà mình vừa nghĩ ra đó là kiểm duyệt nội dung của lời thoại phim, bạn có thể sử dụng phương pháp này để xem các từ lóng hoặc từ bậy xuất hiện bao nhiêu lần trong phim, từ đó đánh giá các cấp độ của phim có phù hợp với trẻ em hay không. Hiện nay công nghệ khá phát triển người ta có thể kiêm duyệt cả hình ảnh và âm thanh bằng máy như Youtube đang làm để chống vi phạm bản quyền.
Vậy là 50 từ này xuất hiện tổng cộng hơn 120 ngàn lần trong văn bản. Bằng cách lấy len() của text1, ta thấy 50 từ chiếm phân nửa số từ trong văn bẳn text1. Bạn có thể sử dụng phương pháp tính phân bố theo tần xuất này để xác định các từ được sử dụng nhiều trong các bài báo, bài viết hay các Status trên mạng xã hội để xem từ nào đang là Trend nhé. Một ví dụ nữa mà mình vừa nghĩ ra đó là kiểm duyệt nội dung của lời thoại phim, bạn có thể sử dụng phương pháp này để xem các từ lóng hoặc từ bậy xuất hiện bao nhiêu lần trong phim, từ đó đánh giá các cấp độ của phim có phù hợp với trẻ em hay không. Hiện nay công nghệ khá phát triển người ta có thể kiêm duyệt cả hình ảnh và âm thanh bằng máy như Youtube đang làm để chống vi phạm bản quyền.
Lựa chọn các từ theo điều kiện.
Bài toán: Lấy các từ có nhiều hơn 15 ký tự trong văn bản.
"Ta chọn thuộc tính P, sao cho P(w) là đúng khi và chỉ khi w có nhiều hơn 15 ký tự." - đây là một dạng diễn giải, giờ ta thử biểu diễn nó ở dạng toán học xem sao.
1. { w | w ∈ V & P(w) }
Hẳn là bạn có thể đọc nó một cách dễ dàng với sự diễn giải phía trên. Bây giờ hãy chuyển nó sang dạng giả mã xem sao.
2. [w for w in V if P(w)]
OK. Cuối cùng thì chuyển nó sang dạng mã Python nhé, ở đây mình sẽ dùng List comprehension để buổi diễn việc lấy ra các từ có nhiều hơn 15 ký tự trong văn bản text1, cùng xem kết quả.
V = set(text1) long_words = [w for w in V if len(w) > 15] sorted(long_words) ['CIRCUMNAVIGATION', 'Physiognomically', 'apprehensiveness', 'cannibalistically', 'characteristically', 'circumnavigating', 'circumnavigation', 'circumnavigations', 'comprehensiveness', 'hermaphroditical', 'indiscriminately', 'indispensableness', 'irresistibleness', 'physiognomically', 'preternaturalness', 'responsibilities', 'simultaneousness', 'subterraneousness', 'supernaturalness', 'superstitiousness', 'uncomfortableness', 'uncompromisedness', 'undiscriminating', 'uninterpenetratingly']Bạn có thể dễ dàng hiểu đoạn mã trên làm gì phải không nào.
Bài toán: Lấy các từ có nhiều hơn 7 ký tự và xuất hiện nhiều hơn 7 lần trong văn bản.
Bây giờ hãy cùng thử với text5 nhé
>>> fdist5 = FreqDist(text5) >>> sorted([w for w in set(text5) if len(w) > 7 and fdist5[w] > 7]) ['#14-19teens', '#talkcity_adults', '((((((((((', '........', 'Question', 'actually', 'anything', 'computer', 'cute.-ass', 'everyone', 'football', 'innocent', 'listening', 'remember', 'seriously', 'something', 'together', 'tomorrow', 'watching']Ở đây thì thuộc tính P được biểu diễn bởi 2 điều kiện là nhiều hơn 7 ký tự và xuất hiện nhiều hơn 7 lần. Ngoài ra bạn có thể sử dụng các điều kiện lọc khác nhé, hãy nhớ sử dụng List comprehension để code được ngắn gọn nhé.
Collocations và Bigrams
Hai từ này dịch ra tiếng Việt thì không hay lắm, cho nên mình sẽ để từ gốc, cũng để tiện cho các bạn tìm hiểu sau này. Collocations hiểu đơn giản là sự kết hợp của từ để tạo thành một từ mới hoặc 1 câu có ý nghĩa. Ví dụ từ "thiên nga đen" là một Collocation, hay "chó trắng" cũng tương tự. Vì có nhiều từ đơn lẻ sẽ không có ý nghĩa khi đứng một mình, nên trong 1 câu ra phải tìm ra các cặp Collocations để máy tính có thể hiểu được ý nghĩa của một câu. Bây giờ chúng ta làm thế nào để tách được riêng các cặp Collocations trong 1 câu đây?. Câu trả lời là sử dụng Bigrams. Ví dụ với câu "Donald Trump is president 45th of America and very rich". Ta sử dụng hàm bigrams()
>>> import nltk >>> bigrm = list(nltk.bigrams("Donald Trump is president 45th of America and very rich".split())) >>> bigrm [('Donald', 'Trump'), ('Trump', 'is'), ('is', 'president'), ('president', '45th'), ('45th', 'of'), ('of', 'America'), ('America', 'and'), ('and', 'very'), ('very', 'rich')] >>>Tuy nhiên, khi sử dụng Bigrams thì sẽ có những cụm mà không có nghĩa, do Bigrams đơn giản chỉ là tách từng từ và kết hợp với từ trước và sau của nó. Ngoài ra có những từ đứng 1 mình cũng có ý nghĩa, nhưng nếu sử dụng Bigrams thì nó sẽ không còn ý nghĩa nữa do bị kết hợp với một từ khác. Ta sử dụng hàm collocations() để lấy các collocations trong các đoạn văn mẫu.
>>> text4.collocations() United States; fellow citizens; four years; years ago; Federal Government; General Government; American people; Vice President; Old World; Almighty God; Fellow citizens; Chief Magistrate; Chief Justice; God bless; every citizen; Indian tribes; public debt; one another; foreign nations; political partiesTa thấy kết quả chính xác hơn. Việc tách các collocations là một thao tác cơ bản và khá quan trọng trong NLP. Sau này chúng ta sẽ cùng tìm hiểu kỹ hơn.
Bài tập tự luyện
- Hãy tính độ dài của 50 từ đầu tiên trong văn bản text1
- Hãy tính độ dài của 50 từ xuất hiện nhiều nhất trong văn bản text5.
- Vẽ biểu đồ về sự phân bố độ dài của 50 từ xuất hiện nhiều nhất trong văn bẳn text2.
- Tính phần trăm các từ có 5 ký tự trong văn bản text3.
DEHA AI Lab - Công ty cổ phần DEHA Việt Nam.
Từ khóa » Tách Từ Tiếng Việt Python
-
[PDF] Tách Từ Tiếng Việt - Soict - HUST
-
Thuật Toán Tách Từ
-
Thuật Toán Tách Từ (Tokenizer)
-
Undertheseanlp/word_tokenize: Vietnamese Word Tokenize - GitHub
-
Bài Toán Tách Từ Tiếng Việt | Tìm ở đây
-
Tokenization Là Gì? Các Kỹ Thuật Tách Từ Trong Xử Lý Ngôn Ngữ Tự Nhiên
-
Tokenization Là Gì? Các Kỹ Thuật Tách Từ Trong Xử Lý Ngôn Ngữ Tự Nhiên
-
Tách Từ Trong Xử Lý Ngôn Ngữ Tự Nhiên - Tokenization In NLP
-
Tìm Hiểu Một Vài Phương Pháp Tách Từ Trong Văn Bản Tiếng Việt
-
Xử Lý Tiếng Việt Trong Python - Lập Trình Không Khó
-
Xây Dựng Chương Trình Tóm Tắt Văn Bản (tiếng Việt) đơn Giản Với ...
-
Giới Thiệu Tiền Xử Lý Trong Xử Lý Ngôn Ngữ Tự Nhiên - Kipalog
-
Phân Loại Văn Bản Tiếng Việt Sử Dụng Machine Learning
-
Forum Machine Learning Cơ Bản | Cốc Cốc Chia Sẻ Mã Nguồn Mở ...
-
Công Cụ Tóm Tắt Văn Bản Tiếng Việt Bằng Python - Tài Liệu Text
-
[PDF] Giải Pháp Tách Từ Sử Dụng Mạng Nơ Ron Nhằm Nâng Cao Chất Lượng ...
-
[PDF] Gán Nhãn Từ Loại Tiếng Việt Dựa Trên
-
Phân Loại Văn Bản Tự động Bằng Machine Learning Như Thế Nào?
-
Python — Tách Một Chuỗi được Phân Tách Bằng Dấu Chấm Phẩy Cho ...