How To Write CSV Data To A Table In Hive In Pyspark - ProjectPro
Maybe your like
Recipe Objective: How to Write CSV data to a table in Hive in Pyspark?
In most big data scenarios, DataFrame in Apache Spark can be created in multiple ways: It can be created using different data formats. For example, loading the data from JSON, CSV. Data merging and data aggregation are an essential part of the day-to-day activities in big data platforms. In this scenario, we are going to read CSV data to a table in the Hive database.
Learn Spark SQL for Relational Big Data Procesing
Table of Contents
- Recipe Objective: How to Write CSV data to a table in Hive in Pyspark?
- System requirements :
- Step 1: Import the modules
- Step 2: Create Spark Session
- Step 3: Verify the databases.
- Step 4: Read CSV File and Write to Table
- Step 5: Fetch the rows from the table
- Step 6: Print the schema of the table
- Conclusion
System requirements :
- Install Ubuntu in the virtual machine click here
- Install Hadoop in Ubuntu Click Here
- Install pyspark or spark in Ubuntu. Click here
- The below codes can be run in Jupyter notebook or any python console.
Before working on the hive using pyspark, copy the hive-site.xml file from the hive /conf folder to the spark configuration folder as shown below:

Step 1: Import the modules
In this scenario, we are going to import the pyspark and pyspark SQL modules and also specify the app name as below:
import pyspark from pyspark.sql import SparkSession from pyspark.sql import Row appName= "hive_pyspark" master= "local"
Step 2: Create Spark Session
Here we will create a spark session and enable the Hive support to interact with the hive database.
spark = SparkSession.builder \ .master(master).appName(appName).enableHiveSupport().getOrCreate()
Step 3: Verify the databases.
Here we are going to verify the databases in hive using pyspark as shown in the below:
df=spark.sql("show databases") df.show()
The output of the above lines:

Step 4: Read CSV File and Write to Table
Here we are going to read the CSV file from the local write to the table in hive using pyspark as shown in the below:
datafile=spark.read.csv("/home/bigdata/Downloads/drivers.csv",header=True) datafile.show(5) datafile.write.saveAsTable("drivers_table")
The output of the above lines:
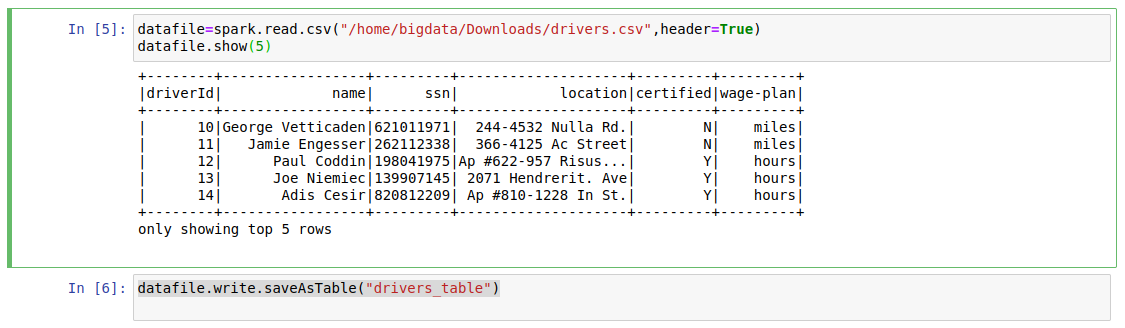
Step 5: Fetch the rows from the table
Here we are going to fetch rows from the table in hive using pyspark and store them in the dataframe as shown below:
df1=spark.sql("select * from drivers_table limit 5") df1.show()
The output of the above lines:
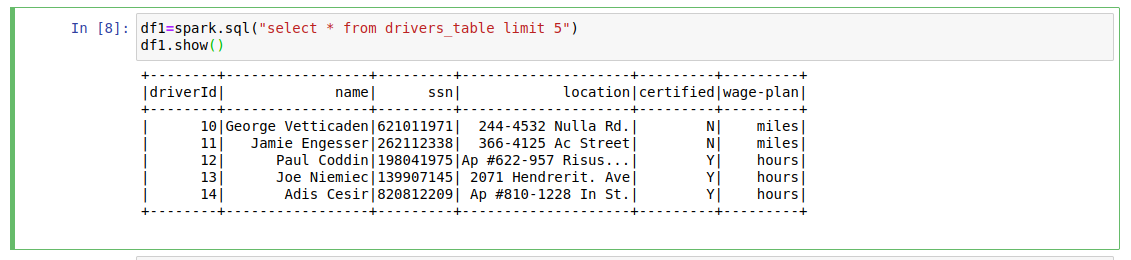
Step 6: Print the schema of the table
Here we are going to print the schema of the table in hive using pyspark as shown below:
df1.printSchema()
The output of the above lines:

Conclusion
Here we learned to write CSV data to a table in Hive in Pyspark.
Tag » How To Add Header Column To Hive Table Csv
-
Export Hive Table Into CSV File With Header? - Spark By {Examples}
-
Hive External Table-CSV File- Header Row - Stack Overflow
-
Create Hive Tables From CSV Files - Cloudera Community - 204532
-
OpenCSVSerDe For Processing CSV - Amazon Athena
-
Query Does Not Skip Header Row On External Table - Azure Databricks
-
CSV Files - Spark 3.3.0 Documentation
-
Export Hive Table Into CSV File With Header? - Pinterest
-
Hive External Table-CSV File- Header Row - Ask Codes
-
Query Does Not Skip Header Row On External Table - Knowledge Base
-
Best Way To Export Hive Table To CSV File | By Ganesh Chandrasekaran
-
Create Hive Table From Csv - Login Page - Yonge Sushi
-
How To Export Apache Hive Data As A CSV File With Headers
-
Create Hive Tables With Headers And Load Quoted CSV Data - Hue