Query Does Not Skip Header Row On External Table - Knowledge Base
Maybe your like
Main Navigation
- Help Center
- Documentation
- Knowledge Base
- Community
- Training
- Feedback
- Home
- All articles
- SQL with Apache Spark
- Query does not skip header row on external table
You are attempting to query an external Hive table, but it keeps failing to skip the header row, even though TBLPROPERTIES ('skip.header.line.count'='1') is set in the HiveContext.
You can reproduce the issue by creating a table with this sample code.
%sql CREATE EXTERNAL TABLE school_test_score ( `school` varchar(254), `student_id` varchar(254), `gender` varchar(254), `pretest` varchar(254), `posttest` varchar(254)) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'dbfs:/FileStore/table_header/' TBLPROPERTIES ( 'skip.header.line.count'='1' )If you try to select the first five rows from the table, the first row is the header row.
%sql SELECT * FROM school_test_score LIMIT 5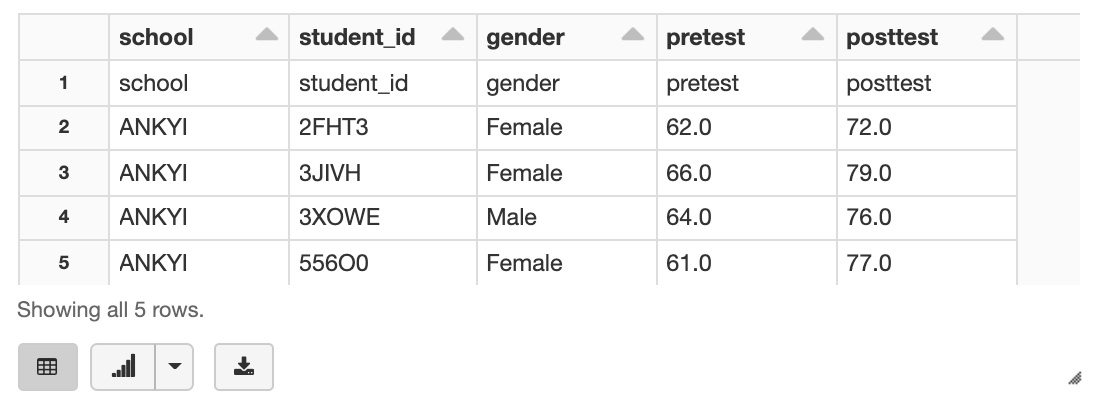
If you query directly from Hive, the header row is correctly skipped. Apache Spark does not recognize the skip.header.line.count property in HiveContext, so it does not skip the header row.
Spark is behaving as designed.
SolutionYou need to use Spark options to create the table with a header option.
%sql CREATE TABLE student_test_score (school String, student_id String, gender String, pretest String, posttest String) USING CSV OPTIONS (path "dbfs:/FileStore/table_header/", delimiter ",", header "true") ;Select the first five rows from the table and the header row is not included.
%sql SELECT * FROM school_test_score LIMIT 5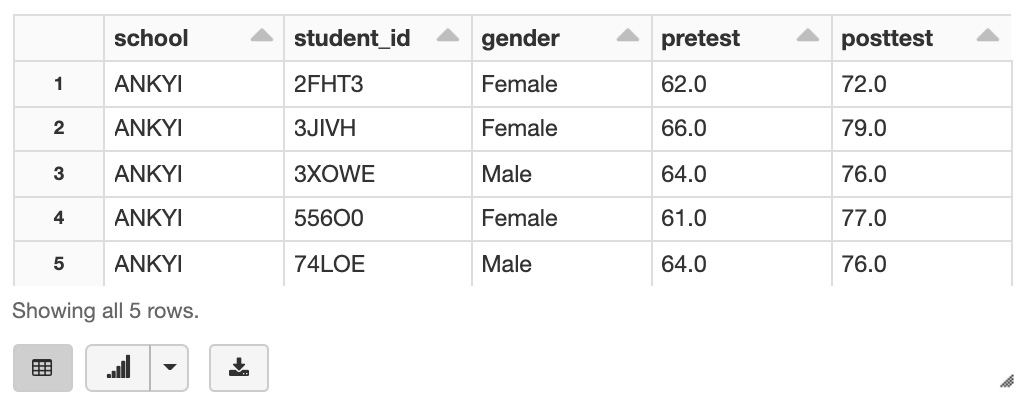
Additional Informations
Related Articles
- Error in SQL statement: AnalysisException: Table or view not found
Problem When you try to query a table or view, you get this error: AnalysisExcept...
- Generate unique increasing numeric values
This article shows you how to use Apache Spark functions to generate unique incre...
- Broadcast join exceeds threshold, returns out of memory error
Problem You are attempting to join two large tables, projecting selected columns ...
- Duplicate columns in the metadata error
Problem Your Apache Spark job is processing a Delta table when the job fails with...
Related Articles
- Error in SQL statement: AnalysisException: Table or view not found
Problem When you try to query a table or view, you get this error: AnalysisExcept...
- Generate unique increasing numeric values
This article shows you how to use Apache Spark functions to generate unique incre...
- Broadcast join exceeds threshold, returns out of memory error
Problem You are attempting to join two large tables, projecting selected columns ...
- Duplicate columns in the metadata error
Problem Your Apache Spark job is processing a Delta table when the job fails with...
If you still have questions or prefer to get help directly from an agent, please submit a request. We’ll get back to you as soon as possible.
Your email address Subject DescriptionPlease enter the details of your request. A member of our support staff will respond as soon as possible.
Tag » How To Add Header Column To Hive Table Csv
-
Export Hive Table Into CSV File With Header? - Spark By {Examples}
-
Hive External Table-CSV File- Header Row - Stack Overflow
-
Create Hive Tables From CSV Files - Cloudera Community - 204532
-
OpenCSVSerDe For Processing CSV - Amazon Athena
-
Query Does Not Skip Header Row On External Table - Azure Databricks
-
CSV Files - Spark 3.3.0 Documentation
-
Export Hive Table Into CSV File With Header? - Pinterest
-
Hive External Table-CSV File- Header Row - Ask Codes
-
Best Way To Export Hive Table To CSV File | By Ganesh Chandrasekaran
-
How To Write CSV Data To A Table In Hive In Pyspark - ProjectPro
-
Create Hive Table From Csv - Login Page - Yonge Sushi
-
How To Export Apache Hive Data As A CSV File With Headers
-
Create Hive Tables With Headers And Load Quoted CSV Data - Hue