Khai Thác Tập Phổ Biến (frequent Itemsets) Với Thuật Toán Apriori
Có thể bạn quan tâm

Bài toán khai thác tập phổ biến (frequent itemset) là bài toán rất quan trọng trong lĩnh vực data mining. Bài toán khai thác tập phổ biến là bài toán tìm tất cả tập các hạng mục (itemset) S có độ phổ biến (support) thỏa mãn độ phổ biến tối thiểu minsupp: 
Dựa trên tính chất của tập phổ biến, ta có phương pháp tìm kiếm theo chiều rộng (thuật toán Apriori (1994)) hay phương pháp phát triển mẫu (thuật toán FP-Growth (2000)). Trong bài viết này, ta sẽ nói về Apriori cùng với một số ví dụ minh họa khi chạy thuật toán này.
Các khái niệm cơ bản
Để minh họa cho các khái niệm, ta lấy ví dụ CSDL với các giao dịch sau.
| TID (mã giao dịch) | Itemset (tập các hạng mục) |
| 1 | A, B, E |
| 2 | B, D |
| 3 | B, C |
| 4 | A, B, D |
| 5 | A, C |
| 6 | B, C |
| 7 | A, C |
| 8 | A, B, C, E |
| 9 | A, B, C |
- Hạng mục (item): mặt hàng A = apple, B = bread, C = cereal, D = donuts, E = eggs.
- Tập các hạng mục (itemset): danh sách các hạng mục trong giỏ hàng như
.
- Giao dịch (transaction): tập các hạng mục được mua trong một giỏ hàng, lưu kèm với mã giao dịch (TID).
- Mẫu phổ biến (frequent item): là mẫu xuất hiện thường xuyên trong tập dữ liệu như
xuất hiện khá nhiều trong các giao dịch.
- Tập k-hạng mục (k-itemset): ví dụ danh sách sản phẩm (1-itemset) như
, danh sách cặp sản phẩm đi kèm (2-itemset) như
, danh sách 3 sản phẩm đi kèm (3-itemset) như
.
- Độ phổ biến (support): được tính bằng
.
là tập các hạng mục, D là cơ sở dữ liệu (CSDL) giao dịch.
- Tập phổ biến (frequent itemset): là tập các hạng mục S (itemset) thỏa mãn độ phổ biến tối thiểu (minsupp – do người dùng xác định như 40% hoặc xuất hiện 5 lần). Nếu
- Tập phổ biến tối đại (max pattern) thỏa
- không tồn tại |X’| > |X|, với X’ cũng phổ biến
- Tập phổ biến đóng (closed pattern) thỏa
- không tồn tại |X’| > |X| mà supp(X’) = supp(X)
- Luật kết hợp (association rule): kí hiệu
, nghĩa là khi X có mặt thì Y cũng có mặt (với xác suất nào đó). Ví dụ,
;
;
.
- Độ tin cậy (confidence): được tính bằng
.

Ta có thể biến đổi CSDL về dạng nhị phân để dễ tính toán.
| TID (mã giao dịch) | A | B | C | D | E |
| 1 | 1 | 1 | 0 | 0 | 1 |
| 2 | 0 | 1 | 0 | 1 | 0 |
| 3 | 0 | 1 | 1 | 0 | 0 |
| 4 | 1 | 1 | 0 | 1 | 0 |
| 5 | 1 | 0 | 1 | 0 | 0 |
| 6 | 0 | 1 | 1 | 0 | 0 |
| 7 | 1 | 0 | 1 | 0 | 0 |
| 8 | 1 | 1 | 1 | 0 | 1 |
| 9 | 1 | 1 | 1 | 0 | 0 |
Bài toán khai thác luật kết hợp
Cho độ phổ biến tối thiểu (minsupp) và độ tin cậy tối thiểu (minconf) do người dùng xác định.
Cho tập các hạng mục 
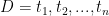
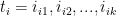
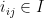
Bài toán khai thác luật kết hợp là bài toán tìm tất cả các luật dạng 
Quy trình khai thác luật kết hợp
Bước 1: Tìm tất cả các tập phổ biến (theo ngưỡng minsupp).
Bước 2: Xây dựng luật từ các tập phổ biến
- Đối với mỗi tập phổ biến S, tạo ra tất cả các tập con khác rỗng của S.
- Đối với mỗi tập con khác rỗng A của S (|A| < |S|). Luật
là luật kết hợp cần tìm nếu:
.
Từ bài toán khai thác luật kết hợp chuyển thành bài toán khai thác tập phổ biến : độ phức tạp tính toán cao.
Thuật toán tìm kiếm theo chiều rộng Apriori
Nguyên tắc loại bỏ của Apriori: Nếu không phải là tập phổ biến thì tập bao nó cũng không phổ biến.
Phương pháp:
- Tìm tất cả các tập phổ biến 1- hạng mục (
).
- Tạo các tập ứng viên kích thước k-hạng mục (k – candidate itemset) từ các tập phổ biến có kích thước (k-1)-hạng mục. Ví dụ, tạo ứng viên
từ tập phổ biến
- Kiểm tra độ phổ biến của các ứng viên trên CSDL và loại các ứng viên không phổ biến ta được
.
- Dừng khi không tạo được tập phổ biến hay tập ứng viên
hay
.
Ví dụ thuật toán Apriori với minsupp = 50%

Mã giả
# buoc 2: loai bo de giam so luong C_{k+1} # Input: # c: tap ung vien kich thuoc k+1 # L_k: tap pho bien (frequent itemset) kich thuoc k # Output: # True/False def has_infrequent_subset(c, L_k): for subset in c: if subset not in L_k: return True return False # buoc 3: tao tap ung vien k+1-hang muc # gom 2 buoc join + prune # Input: # L_k: tap pho bien (frequent itemset) kich thuoc k # Output: # C_{k+1}: tap ung vien kich thuoc k+1 def apriori_gen(L_k): # tap ung vien kich thuoc k+1 C_k_1 = [] for i1 in L_k: for i2 in L_k: # generate candidate by check length range_k = range(len(i1)) # range_k = {0, 1, ..., k-1} for k in range_k: if i1[k] == i2[k]: # make sure generate only 1 additional item continue if i1[k] = minsupp: L_k = C_k_1 L.append(L_k) return LĐánh giá thuật toán
Apriori là thuật toán đơn giản, dễ hiểu và dễ cài đặt. Tuy nhiên, Apriori có các nhược điểm như:
- Phải duyệt CSDL nhiều lần. Với
, số lần duyệt CSDL sẽ là 100.
- Số lượng tập ứng viên rất lớn:
.
- Thực hiện việc tính độ phổ biến nhiều, đơn điệu.
Cải tiến Apriori : ý tưởng chung
- Giảm số lần duyệt CSDL
- Giảm số lượng tập ứng viên
- Qui trình tính độ phổ biến thuận tiện hơn
Tham khảo thêm: http://www.kdnuggets.com/2016/04/association-rules-apriori-algorithm-tutorial.html
Có liên quan
Từ khóa » Khái Niệm Apriori
-
Tiên Nghiệm – Wikipedia Tiếng Việt
-
Apriori Là Gì? Định Nghĩa, Ví Dụ, Giải Thích - Sổ Tay Doanh Trí
-
Apriori - Tra Cứu Từ định Nghĩa Wikipedia Online
-
Thuật Toán Apriori Khai Phá Luật Kết Hợp Trong Data Mining - Viblo
-
Thuật Toán Apriori Trong Data Mining - W3seo Khai Thác Luật Kết Hợp
-
THUẬT TOÁN APRIORI
-
Apriori Tiếng Anh Là Gì? - Từ điển Anh-Việt
-
Định Nghĩa Apriori Algorithm Là Gì?
-
Tiên Nghiệm, Cái (a Priori) Là Gì ? - Luật Minh Khuê
-
Tìm Hiểu Về Association Rules – Apriori (Khai Phá Luật Kết Hợp) (P.3)
-
[PDF] Khai Phá Mẫu Phổ Biến Và Luật Kết Hợp
-
Khai Phá Dữ Liệu Với Thuật Toán Apriori (Phần 1) - Quanghuy
-
Tổng Quan Về Khai Phá Dữ Liệu Và Phương Pháp Khai Phá Luật Kết ...
-
Thuật Toán Apriori Khai Phá Luật Kết Hợp - BIS