Tạo Language Model để Tự động Sinh Văn Bản Tiếng Việt - Viblo
Có thể bạn quan tâm
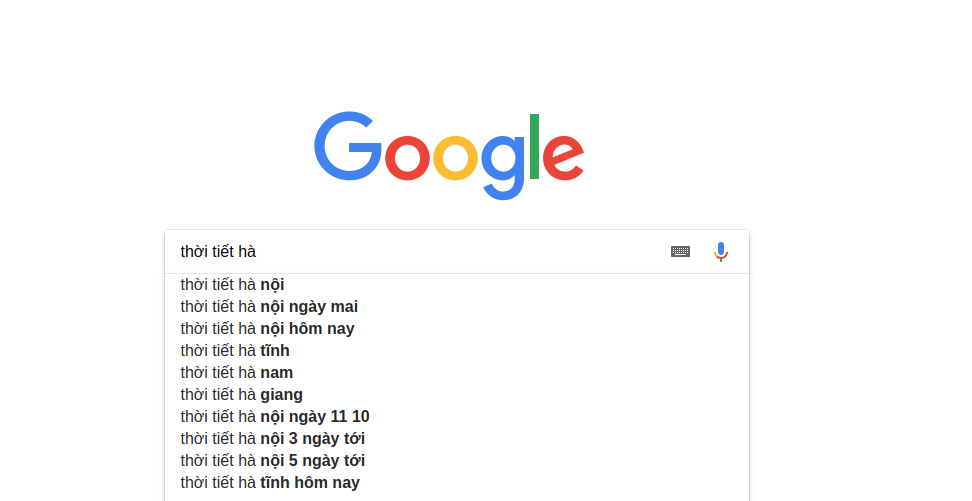
Đây không còn là một điều quá lạ lẫm với chúng ta, tuy nhiên đó vẫn là một tính năng tuyệt vời giúp tăng trải nghiệm cho người dùng của Google. Khi bạn bắt đầu gõ vào ô tìm kiếm của trên trang Google Search, bạn có thể nhìn thấy ngay vài từ tiếp theo, thậm chí là tất cả phần còn lại ở phần gợi ý tìm kiếm. Hệ thống của Google Search sử dụng một thuật toán để tự động tạo ra những gợi ý này mà không hề có sự can thiệp của con người (không phải là ý kiến, câu hỏi của một ai đó khác hay của Google), và một phần trong số đó liên quan đến bài viết lần này mình muốn giới thiệu: Language Model
Mục tiêuĐúng như tiêu đề, hôm nay mình sẽ giới thiệu cho các bạn cách để tạo ra Language Model bằng việc sử dụng một mạng RNN đơn giản của Deep Learning, từ đó chúng ta sẽ thử cho mô hình sinh ra các đoạn văn bản để xem và đánh giá tính hiệu quả của nó.
Language Model là gìNếu như các bạn đã và đang tìm hiểu về lĩnh vực Xử lý ngôn ngữ tự nhiên (Natural Language Processing) thì đây có lẽ cũng không còn là một thuật ngữ xa lạ. Mục đích của mô hình này là để cung cấp phân bố xác suất tiền nghiệm (prior distribution), từ đó giúp chúng ta biết được một câu có "hợp lý" với ngôn ngữ xác định hay không (ở đây là tiếng việt) hoặc một từ thêm vào sau 1 câu có đúng ngữ cảnh và ăn khớp với các từ ở trước đó hay không.
Ví dụ một cách đơn giản các bạn có thể nhìn thấy như câu ở trên, với đầu vào là "thời tiết hà" thì xác suất của từ/cụm từ tiếp theo "nội" và các từ như "tĩnh", "giang" sẽ cao hơn xác suất của nhiều từ khác. Trong thời gian gần đây, Language Model đóng vai trò quan trọng trong rất nhiều ứng dụng, bài toán của Xử lý ngôn ngữ tự nhiên và đang là chủ đề nghiên cứu thu hút được nhiều sự quan tâm của các lập trình viên, nhà nghiên cứu trên toàn thế giới. Tuy nhiên, do mỗi quốc gia, sẽ sử dụng một ngôn ngữ khác nhau với cấu trúc ngữ pháp, văn hóa, hình thức nói khác nhau, dẫn đến việc Language Model cho từng ngôn ngữ sẽ phải giải quyết nhiều bài toán đặc thù của nó. Trong phần tiếp theo, chúng ta sẽ cùng nhau xây dựng một "Mô hình ngôn ngữ" (Language Model) dành cho tiếng Việt!

Cũng giống như hầu hết các bài toán Machine Learning khác, để giải quyết bài toán lần này, chúng ta sẽ phải thực hiện 2 bước chính:
- Xử lý dữ liệu (Data Pre-processing)
- Xây dựng mô hình và training mô hình
1. Xử lý dữ liệu
Điều đầu tiên là đi tìm kiếm và thu thập dữ liệu. Với bài toán lần này, mình có tìm kiếm được tập dữ liệu bao gồm hơn 40000 bài báo/bản tin, thuộc 8 lĩnh vực khác nhau. Các bạn có thể tiến hành tải tập dữ liệu này xuống ở đây:
https://github.com/hoanganhpham1006/Vietnamese_Language_Model/blob/master/Train_Full.zip
Tuy nhiên chúng ta cũng sẽ không cần sử dụng hết tất cả chỗ này, mình sẽ chỉ sử dụng khoảng 1/4 lượng dữ liệu nêu trên.
Tiến hành đọc thử 1 file dữ liệu chúng ta sẽ có được kết quả như sau:
Đóng cửa mọi ngả đường chuyển gia cầm vào TP HCM\nNgày 15/1, lực lượng thú y phối hợp với cảnh sát, thanh tra giao thông TP HCM mở điểm kiểm soát trên mọi ngả đường ngoại ô. Thực hiện công điện của Bộ Nông nghiệp và phát triển nông thôn trước đó một ngày, lực lượng chức năng đã chặn không để con gà nào từ tỉnh ngoài lọt vào thành phố.\nTại Trạm Kiểm dịch động vật huyện Bình Chánh, cửa ngõ phía Tây của thành phố, Phó trạm Phạm Ngọc Lanh mắt thâm quầng nói: "Từ khi xảy ra dịch đến giờ, anh em thay nhau túc trực ở đây....
Nhìn qua chúng ta sẽ thấy một vài vấn đề như sau:
- Chữ viết hoa/ viết thường lẫn lộn: Với chúng ta đây là 1 điều bình thường, tuy nhiên máy tính phân biệt khác nhau giữa chữ in hoa và chữ in thường, và điều này làm tăng độ phức tạp khi xử lý mặc dù và cơ bản, ý nghĩa của từ khi viết hoa hay viết thường vẫn là không thay đổi.
- Nhiều dấu câu và ký tự thừa: Các dấu chấm, phẩy, các ký tự lạ xuất hiện nhiều lần trong văn bản. Điều này cũng sẽ làm cho việc xử lý trở nên khó khăn và tốn thời gian hơn
- Một số ký tự viết tắt/ tên riêng: TP HCM
Chúng ta sẽ thực hiện một vài thuật toán để giải quyết các vấn đề trên bao gồm:
- Ghép các từ tiếng Việt lại trước khi tách ra để đảm bảo vẫn giữ được ngữ nghĩa
- Đưa tất cả về dạng chữ thường
- Loại bỏ tất cả các dấu câu, ký tự thừa.
Kết quả thu được sau bước này sẽ là một danh sách các từ
['đóng_cửa', 'mọi', 'ngả', 'đường', 'chuyển', 'gia_cầm', 'vào', 'tp', 'hcm', 'ngày', '151', 'lực_lượng',...]
Làm như vậy với tất cả các văn bản mà các bạn muốn sử dụng, mỗi văn bản chúng ta sẽ thu được 1 danh sách từ tương ứng. Tuy nhiên, đây chưa phải là cái mà chúng ta cần để cho vào mô hình của chúng ta. Mô hình RNN Với mục đích đưa vào một đoạn văn bản (một số lượng từ, câu) và để dự đoán ra từ tiếp theo, mô hình RNN chúng ta xây dựng lần này sẽ lấy đầu vào là 50 từ (số lượng từ là tùy vào các bạn) và đầu ra sẽ là 1 từ. Như vậy dữ liệu chúng ta đưa vào training sẽ là nhiều đoạn 51 từ, lấy 50 từ làm dữ liệu training (data) và 1 từ cuối cùng của câu đó làm kết quả (labels).
INPUT_LENGTH = 50 sequences = [] for f in file_list: f1 = open(f, encoding='utf-16') doc = f1.read() tokens = clean_document(doc) for i in range(INPUT_LENGTH + 1, len(tokens)): seq = tokens[i-INPUT_LENGTH-1:i] line = ' '.join(seq) sequences.append(line)Ở trong phần code trên, mình có 1 file_list bao gồm tên các file, mỗi file chứa 1 văn bản. Với mỗi văn bản, mình thực hiện phần tiền xử lý, sau đó từ 1 văn tạo, cứ 51 từ liên tiếp ta nối lại với nhau (50 từ đầu dùng làm dữ liệu, 1 từ cuối làm nhãn) để tạo ra chuối training. (Từ đầu tiên đến từ thứ 51 là 1 chuỗi, từ thứ 2 đến từ thứ 52 là một chuỗi,...) Bước cuối cùng của tiền xử lý là chúng ta sẽ phải thực hiện "số hóa" cho tất cả các từ trong các chuỗi mà t đang có. Tất cả các mô hình Deep Learning hiện nay đều xử lý, tối ưu bằng các phép toán trên số và Mô hình RNN để xây dựng Language Model của chúng ta cũng sẽ không phải ngoại lệ. Có nhiều phương pháp để thực hiện công việc này (bài viết lần trước mình đã giới thiệu sơ qua tới các bạn phương pháp word2vec - mỗi một từ chúng ta sẽ biểu diễn bởi 1 vector, trong bài viết lần này, mình muốn giới thiệu tới các bạn một phương pháp khác đơn giản hơn nữa. Chúng ta sẽ xây dựng nên 1 bảng tương ứng, mà mỗi từ khác nhau sẽ được ký hiệu bởi số nguyên khác nhau duy nhất. Keras có hỗ trợ chúng ta trong việc xây dựng nên bảng này với hàm keras.preprocessing.text.Tokenizer
tokenizer = keras.preprocessing.text.Tokenizer(filters='!"#$%&()*+,-./:;<=>?@[\]^`{|}~ ') tokenizer.fit_on_texts(sequences)Filter ở đây là các ký tự sẽ được bỏ qua, ở đây do chúng ta đã muốn xử lý với tiếng Việt (các từ tiếng Việt trong bước trước đã được chúng ta đánh dấu bằng ký tự "_": "đóng_cửa",'gia_cầm'.. nên mình đã bỏ ký tự "" khỏi tham số filter)
Hàm fit_on_texts giúp chúng ta xây dựng nên bảng để tương ứng từ sang các số như chúng ta cần.
Các bạn có thể sử dụng hàm để thấy bảng kết quả tokenizer.word_indexSau khi đã có bảng, chúng ta thực hiện chuyển từng từ thành số tương ứng ở trong tất cả các chuỗi sequences_digit = tokenizer.texts_to_sequences(sequences){ 'cổng_chào': 30919, 'thà': 3224, '114': 17777, 'trần_bình_minh': 16017, 'trừu_tượng_hoá': 23416,'trái_đất': 3944,'nguyễn_thị_xuân_phượng': 27864, 'chia_lìa': 12470, 'chocolate': 5705,'dường_như_họa_sĩ': 34437,'natalie_zhu': 30224, 'narain': 32563,...}
Chạy xong đến đây, chúng ta sẽ có được 1 tập các chuỗi số để sẵn sàng sang phần tiếp theo.!!
2. Xây dựng và huấn luyện Language Model
Trước khi đưa dữ liệu vào để có thể training, chúng ta cần khai báo và chuẩn hóa đầu vào và đầu ra
# separate into input and output sequences_digit = array(sequences_digit) X, y = sequences_digit[:,:-1], sequences_digit[:,-1] y = keras.utils.to_categorical(y, num_classes=vocab_size) seq_length = X.shape[1]Ta sẽ tách toàn bộ các chuỗi ra làm 2 phần như đã dự định từ ban đầu, 50 từ đầu tiên (từ đầu tiên đến từ áp chót) là dữ liệu training và từ cuối cùng làm labels Tiếp theo, labels của chúng ta sẽ đưa về dạng vector one-hot bằng cách sử dụng hàm to_categorical của keras.util Mô hình RNN cho Language Model của chúng ta sử dụng lần này sẽ chỉ có 2 lớp LSTM như sau:
vocab_size = len(tokenizer.word_index) + 1 model = Sequential() model.add(Embedding(vocab_size, 50, input_length=50)) model.add(BatchNormalization()) model.add(LSTM(512, return_sequences=True)) model.add(LSTM(512)) model.add(Dense(100, activation='relu')) model.add(Dropout(0.2)) model.add(BatchNormalization()) model.add(Dense(vocab_size, activation='softmax')) model.summary() model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])Để giảm thời gian training, 2 lớp LSTM ở đây mình chỉ dùng 512 units. Sau khi đưa qua 2 lớp LSTM, mình sử dụng 1 lớp Dense đưa ra 100 đầu ra và cuối cùng sử dụng 1 lớp Dense nữa để có số lượng đầu ra bằng với số lượng từ có trong từ điển (vocab_size). Mọi thứ đã chuẩn bị xong, giờ là lúc để bắt đầu (ngồi đợi...) huấn luyện mô hình
model.fit(X, y, batch_size=512, epochs=100)Chúng ta sẽ chờ đợi kết quả nhé, mình đang sử dụng GPU trên Google Colab, cũng phải mất tới hơn 15 phút cho 1 epoch training (mình đang dùng 1 triệu chuỗi dữ liệu cho bài toán lần này), mình dự kiến sẽ training 100 epoch..
Epoch 1/100 1953/1953 [==============================] - 1234s 624ms/step - loss: 5.0340 - acc: 0.1684 Epoch 2/100 1953/1953 [==============================] - 1233s 624ms/step - loss: 4.9822 - acc: 0.1726 ... Epoch 99/100 1953/1953 [==============================] - 1310s 671ms/step - loss: 2.1418 - acc: 0.5137 Epoch 100/100 1150/1953 [================>.............] - ETA: 8:58 - loss: 2.1458 - acc: 0.5125Sau khi training xong 100 epoch, chúng ta đã có một model với độ chính xác 51.25%, ở đây mình đã chủ động kết thúc sớm việc training do mình chỉ muốn dừng lại ở mức độ chính xác này. Độ chính xác quá cao sẽ khiến Language Model có xu hướng "học thuộc lòng" và mất đi "tính sáng tạo" cần thiết, độ chính xác này đã là đảm bảo được khả năng hiểu về ngữ cảnh của model. Nếu muốn các bạn có thể tiếp tục training thêm. Chúng ta sẽ lưu lại mô hình này để sử dụng, kèm theo đó, chúng ta sẽ cần phải lưu lại tokenizer (bảng tham chiếu từng từ sang số) thành 1 file pkl để đảm bảo quá trình giải mã về sau là chính xác. Lần này, mình cũng tiến hành lưu lại luôn sequences_digit để không mất thời gian chuyển đổi lại từ các từ sang số.
import pickle model.save('51_acc_language_model.h5') with open('tokenizer.pkl', 'wb') as f: pickle.dump(tokenizer, f) with open('sequences_digit.pkl', 'wb') as f: pickle.dump(sequences_digit, f)Vậy là đã hoàn thành việc huấn luyện cho mô hình, chúng ta đã có trong tay Language Model dành riêng cho tiếng Việt. Với việc tối giản hóa mọi thứ, hy vọng các bạn đã đều thực hiện thành công tới bước này ^^
Thử nghiệm sinh văn bản với Language ModelNếu bạn thực hiện việc thử nghiệm này ở một file mới, môi trường mới, thì trước hết, hãy thực hiện việc tải lại model, tokenizer
import pickle from keras.models import load_model with open('tokenizer.pkl', 'rb') as f: tokenizer = pickle.load(f) with open('sequences_digit', 'rb') as f: sequences_digit = pickle.load(f) model = load_model('51_acc_language_model.h5')Để model của chúng ta có thể sinh ra được văn bản, đầu tiên, chúng ta cần cung cấp và xử lý đầu vào. Đầu vào của chúng ta sẽ là một đoạn văn bản bất kỳ nào đó, chúng sẽ phải được chuẩn hóa và sau đó là mã hóa tương ứng thành các số trong bảng giống hệt như cách mà chúng ta đã dùng khi chúng ta thực hiện huấn luyện mô hình
import numpy as np def preprocess_input(doc): tokens = clean_document(doc) tokens = tokenizer.texts_to_sequences(tokens) tokens = keras.preprocessing.sequence([tokens], maxlen=50, truncating='pre') return np.reshape(tokens, (1,50))Trong đoạn code ở trên, mình có sử dụng thêm một hàm pad_sequences của keras. Mục đích của việc này là để đảm bảo đầu vào của chúng ta luôn là 1 chuỗi có 50 phần tử. Nếu ta đưa vào 1 chuỗi nhỏ hơn 50 phần tử, ta sẽ thêm vào đầu tiên những ký tự rỗng cho đến khi đủ 50 phần tử thì thôi.
Để thực hiện việc "dự đoán" từ tiếp theo có xác suất xuất hiện cao nhất từ chuỗi đầu vào của chúng ta, chúng ta sẽ chỉ cần thực hiện một lệnh đơn giản đó là gọi lệnh predict_classes của model model.predict_classes(tokens)Kết quả trả ra sẽ là 1 số tương ứng với 1 từ nào đó có xác suất xuất hiện cao nhất đối với chuối đầu vào của chúng ta. Sau đó, tôi sẽ thực hiện nối từ này vào chuối đầu vào, rồi để Language Model tiếp tục dự đoán từ tiếp theo, cứ làm như vậy cho tới khi sinh ra đủ số từ mà chúng ta đang mong đợi
def generate_text(text_input, n_words): tokens = preprocess_input(text_input) for _ in range(n_words): next_digit = model.predict_classes(tokens) tokens = np.append(tokens, next_digit) tokens = np.delete(tokens, 0) tokens = np.reshape(tokens, (1, 50)) # Mapping to text tokens = np.reshape(tokens, (50)) out_word = [] for token in tokens: for word, index in tokenizer.word_index.items(): if index == token: out_word.append(word) break return ' '.join(out_word)Khi đã có 1 chuỗi được sinh ra, điều cuối cùng chúng ta cần phải làm đó là giải mã chuỗi đầu ra thành các từ tiếng Việt tương ứng, rồi thực hiện ghép lại thành câu.
Dưới đây là một số kết quả mình đã thử nghiệm được từ việc cho Language Model của mình sinh ra văn bản: Inputđường phố ở việt nam
Output
tạo nhiều nét của các nghệ_nhân chính_trị khác nhiều tác_phẩm được coi là nơi có nhiều cột đồ thu_hút được được đánh_giá là có giá_trị
Input
Tại buổi đối thoại, nhiều doanh nghiệp cho biết hằng năm họ phải tiếp nhiều đoàn thanh tra, kiểm tra từ các cấp, việc này vô tình gây mất thời gian, phiền hà
Output
Kết quả được sinh ra trông có vẻ hợp lý với ngữ cảnh của đầu vào. Trên thực tế, việc sinh văn bản sẽ còn được hỗ trợ thêm nhiều các thông tin khác, nhưng ở đây, chúng ta chỉ cần một đoạn văn đầu vào cũng đã là đủ. Các bạn hãy thử đưa đầu vào và sinh ra văn bản với mô hình của mình nhé! Tổng kếtlớn hơn cả năm nay các nhà đầu_tư lại thất_nghiệp vừa minh_bạch 2 usd trong khi nhà_nước có_thể xuất mức lãi_suất đang được tiếp_tục tiếp_tục
Qua bài chia sẻ lần này, mình đã cố gắng để giới thiệu tới các bạn một trong những cách để xây dựng nên một Language Model dành cho tiếng Việt - vấn đề đang rất được quan tâm hiện nay và là cốt lõi trong các hệ thống Xử lý ngôn ngữ tự nhiên. Với cấu trúc mạng đơn giản (RNN), hy vọng các bạn sẽ không gặp vấn đề gì khó khăn khi xây dựng mô hình này theo mình.
Tổng kết lại sẽ có vài điều mà các bạn nên chú ý trong bài viết:- Phương pháp tiền xử lý dữ liệu văn bản cho việc huấn luyện Language Model
- Phương pháp xây dựng và huấn luyện Language Model
- Cách hoạt động của Language Model và sử dụng mô hình vừa được huấn luyện để sinh ra văn bản.
Trong quá trình làm, nếu có vấn đề gì xảy ra hay có câu hỏi, các bạn hãy để lại ở dưới phần comment, mình sẽ giải đáp nhanh nhất có thể để giúp các bạn xây dựng được thành công Language Model.
Để tiện theo dõi hơn cho các bạn, thì đây là link repo trên github của bài viết này:https://github.com/hoanganhpham1006/Vietnamese_Language_Model Cảm ơn các bạn đã quan tâm theo dõi ^^
Từ khóa » Tách Từ Tiếng Việt Vntokenizer
-
V. Tìm Hiểu Opensource Vntokenizer để Tách Từ Trong Văn Bản Tiếng ...
-
Cách Tách Từ Cho Tiếng Việt
-
Chương Trình Tách Từ VnTokenizer, Version 4.1.1. - GitHub
-
[PDF] Tách Từ Tiếng Việt - Soict - HUST
-
VnTokenizer - Tách Từ Tiếng Việt Tự động - Vietnamese Unicode FAQs
-
Nghiên Cứu Một Số Kỹ Thuật Tách Từ Trong Xử Lý Ngôn Ngữ... - ĐHKG
-
Bài Tập Lớn Xử Lý Ngôn Ngữ Tự Nhiên đề Tài Tìm Hiểu Phương Pháp ...
-
Thuật Toán Tách Từ (Tokenizer)
-
Thuật Toán Tách Từ
-
[PDF] Sự ảnh Hưởng Của Phương Pháp Tách Từ Trong Bài Toán
-
[PDF] Giải Pháp Tách Từ Sử Dụng Mạng Nơ Ron Nhằm Nâng Cao Chất Lượng ...
-
Ứng Dụng Phương Pháp Pointwise Vào Bài Toán Tách Từ Cho Tiếng Việt
-
Bài Toán Tách Từ Tiếng Việt | Tìm ở đây
-
Tách Từ Trong Xử Lý Ngôn Ngữ Tự Nhiên - Tokenization In NLP
-
Kỷ Lục Tách Từ | Xử Lý Tiếng Việt Wiki | Fandom
-
Bài Toán Tách Từ By Susu Dihoc - Prezi
-
Xin Hương Dẫn Về Việc Gọi Một Chương Trình Khác Trong Chương ...
-
[PDF] ĐỒ ÁN TỐT NGHIỆP
-
Chạy VnTokenizer Trên Môi Trường Apache Spark - Tôi Là Duyệt