Tìm Kiếm Theo Chiều Sâu – Wikipedia Tiếng Việt
| Thuật toán tìm kiếm theo chiều sâu | |
 | |
| Ví dụ về thứ tự duyệt theo chiều sâu | |
| Phân loại | Thuật toán tìm kiếm |
| Cấu trúc dữ liệu | Đồ thị |
| Độ phức tạp thời gian | O(|V|+|E|) với đơn đồ thị, không duyệt vòng |
| Độ phức tạp không gian | O(|V|) nếu duyệt toàn bộ đồ thị, mỗi đỉnh qua đúng một lần |
| Thuật toán tìm kiếmcây và đồ thị |
|---|
|
| Danh sách |
|
| Liên quan |
|
|
Tìm kiếm ưu tiên chiều sâu hay tìm kiếm theo chiều sâu (tiếng Anh: Depth-first search - DFS) là một thuật toán duyệt hoặc tìm kiếm trên một cây hoặc một đồ thị. Thuật toán khởi đầu tại gốc (hoặc chọn một đỉnh nào đó coi như gốc) và phát triển xa nhất có thể theo mỗi nhánh.
Thông thường, DFS là một dạng tìm kiếm thông tin không đầy đủ mà quá trình tìm kiếm được phát triển tới đỉnh con đầu tiên của nút đang tìm kiếm cho tới khi gặp được đỉnh cần tìm hoặc tới một nút không có con. Khi đó giải thuật quay lui về đỉnh vừa mới tìm kiếm ở bước trước. Trong dạng không đệ quy, tất cả các đỉnh chờ được phát triển được bổ sung vào một ngăn xếp LIFO.
Độ phức tạp không gian của DFS thấp hơn của BFS (tìm kiếm theo chiều rộng). Độ phức tạp thời gian của hai thuật toán là tương đương nhau và bằng O(|V| + |E|).
Ví dụ
[sửa | sửa mã nguồn]
Tìm kiếm ưu tiên chiều sâu bắt đầu thăm đỉnh A, đi theo cạnh trái, tiếp tục tìm kiếm xong ở cây con trái mới chuyển sang tìm kiếm ở cây con phải. Thứ tự thăm viếng các đỉnh là: A, B, D, F, E, C, G.
Quá trình viếng thăm các đỉnh diễn ra như sau: Sau khi thăm đỉnh A, vì B chưa được thăm nên theo cạnh AB ta thăm B, tiếp tục theo cạnh BD tới viếng thăm D. Từ D không thể tiếp tục đi xa hơn, ta quay lại B. Từ B, theo BF đến thăm F, tiếp tục theo cạnh FE đến thăm E. Từ E cũng không thể đi xa hơn, quay lại A, duyệt tiếp đến C, G.
Kết quả của thuật toán
[sửa | sửa mã nguồn]Một cách tự nhiên, kết quả của giải thuật tìm kiếm theo chiều sâu là một cây phủ qua tất cả các đỉnh được duyệt của đồ thị.
Duyệt các đỉnh
[sửa | sửa mã nguồn]Có thể dùng giải thuật này để tạo một danh sách tuyến tính các đỉnh của một đồ thị (hoặc cây). Có ba cách hiện thực phương pháp này:
- Duyệt tiền thứ tự (preordering): tạo ra một danh sách mà trong đó các đỉnh xuất hiện theo đúng trật tự nó được thăm đến khi chạy thuật toán. Đây chính là biểu diễn tự nhiên của quá trình thực hiện giải thuật tìm kiếm theo chiều sâu. Một biểu thức ở dạng tiền thứ tự được gọi là ký pháp tiền tố.
- Duyệt hậu thứ tự (postordering): tạo ra một danh sách mà trong đó các đỉnh xuất hiện theo thứ tự của lần duyệt đến sau cùng khi thực hiện giải thuật. Một lần duyệt hậu thứ tự một cây biểu thức sẽ cho ra một ký pháp hậu tố.
- Duyệt đảo hậu thứ tự (reverse postordering): kết quả của cách duyệt này là sự đảo ngược lại thứ tự trong kết quả duyệt hậu thứ tự. Thông thường, khi duyệt cây, cách này cho ra cùng kết quả với duyệt tiền thứ tự, nhưng xét tổng quát, khi duyệt một đồ thị, tiền thứ tự và đảo hậu thứ tự cho ra kết quả khác nhau. Với các đồ thị có hướng và không có vòng, cách duyệt đảo hậu thứ tự cho ra một trật tự tô-pô của đồ thị đó.
Thuật toán tìm kiếm theo chiều sâu trong đồ thị vô hướng[1]
[sửa | sửa mã nguồn]Ý tưởng thuật toán
[sửa | sửa mã nguồn]- DFS trên đồ thị vô hướng cũng giống như khám phá mê cung với một cuộn chỉ và một thùng sơn đỏ để đánh dấu, tránh bị lạc. Trong đó mỗi đỉnh s trong đồ thị tượng trưng cho một cửa trong mê cung.
- Ta bắt đầu từ đỉnh s, buộc đầu cuộn chỉ vào s và đánh đấu đỉnh này "đã thăm". Sau đó ta đánh dấu s là đỉnh hiện hành u.
- Bây giờ, nếu ta đi theo cạnh (u,v) bất kỳ.
- Nếu cạnh (u,v) dẫn chúng ta đến đỉnh "đã thăm" v, ta quay trở về u.
- Nếu đỉnh v là đỉnh mới, ta di chuyển đến v và lăn cuộn chỉ theo. Đánh dấu v là "đã thăm". Đặt v thành đỉnh hiện hành và lặp lại các bước.
- Cuối cùng, ta có thể đi đến một đỉnh mà tại đó tất cả các cạnh kề với nó đều dẫn chúng ta đến các đỉnh "đã thăm". Khi đó, ta sẽ quay lui bằng cách cuộn ngược cuộn chỉ và quay lại cho đến khi trở lại một đỉnh kề với một cạnh còn chưa được khám phá. Lại tiếp tục quy trình khám phá như trên.
- Khi chúng ta trở về s và không còn cạnh nào kề với nó chưa bị khám phá là lúc DFS dừng.
Mệnh đề
[sửa | sửa mã nguồn]Gọi G là một đồ thị vô hướng, trên đó ta sẽ thực hiện thao tác DFS với đỉnh bắt đầu là s thì:
- Phép duyệt sẽ thăm tất cả các đỉnh cùng thành phần liên thông với s.
- Các cạnh có nhãn "đã thăm" sẽ tạo ra một cây tối đại của thành phần liên thông chứa s.
Chứng minh
[sửa | sửa mã nguồn]- Khẳng định 1, là hiển nhiên vì DFS duyệt qua tất cả các đỉnh kề với đỉnh hiện hành (có thể chứng minh hoàn chỉnh hơn bằng phản chứng).
- Khẳng định 2, đúng do ta chỉ đánh dấu các cạnh đi đến một đỉnh mới nên không thể tạo ra chu trình. Như vậy DFS tạo ra một cây. Hơn nữa, DFS thăm tất cả các đỉnh thuộc thành phần liên thông nên cây này là cây tối đại.
Độ phức tạp của thuật toán
[sửa | sửa mã nguồn]- DFS được gọi đúng 1 lần ứng với mỗi đỉnh.
- Mỗi cạnh được xem xét đúng 2 lần, mỗi lần từ một đỉnh kề với nó.
- Với ns đỉnh và ms cạnh thuộc thành phần liên thông chứa s, một phép DFS bắt đầu tại s sẽ chạy với thời gian O(ns + ms) nếu:
- Đồ thị được biểu diễn bằng cấu trúc dữ liệu dạng danh sách kề.
- Đặt nhãn cho một đỉnh là "đã thăm" và kiểm tra xem một đỉnh "đã thăm" chưa tốn chi phí O(degree).
- Bằng cách đặt nhãn cho các đỉnh là "đã thăm", ta có thể xem xét một cách hệ thống các cạnh kề với đỉnh hiện hành nên ta sẽ không xem xét một cạnh quá 1 lần.
Xác định đỉnh kề trong DFS
[sửa | sửa mã nguồn]- Kết quả của DFS phụ thuộc vào cách ta chọn đỉnh kế tiếp.

- Nếu ta bắt đầu tại A và thử cạnh nối đến F, sau đó đến B, rồi đến E, C, cuối cùng là G ta được:

- Nếu cũng bắt đầu từ A nhưng đi theo trình tự, tập các cạnh đã thăm, backedge và các điểm đệ quy sẽ khác trước.

Chạy từng bước thuật toán
[sửa | sửa mã nguồn]Giờ ta sẽ chạy từng bước thuật toán theo ví dụ trên.
Nguyên lý[2]
[sửa | sửa mã nguồn]Khởi đầu từ một đỉnh, đi theo các cung(cạnh) xa nhất có thể. Trở lại đỉnh của cạnh xa nhất, tiếp tục duyệt như trước, cho đến đỉnh cuối cùng.
 | Đoạn này đang chờ cập nhật hướng dẫn chi tiết các bước chạy. Bạn có thể viết thêm cho đoạn này được hoàn thiện hơn. Xem phần trợ giúp để biết thêm về cách sửa đổi bài. Nếu trang này đã hoàn thiện, mời bạn gỡ bản mẫu này. Sửa đổi cuối: TheSecondFunnyYellowBot (thảo luận · đóng góp) vào 3 tháng trước. (làm mới) |
- Bước 1:

- Bước 2:
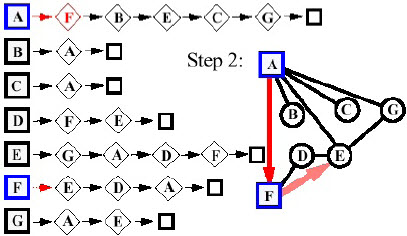
- Bước 3:

- Bước 4:

- Bước 5:

- Bước 6:

- Bước 7:

- Bước 8:

- Bước 9:

- Bước 10:

- Bước 11:

- Bước 12:

- Bước 13:

- Bước 14:
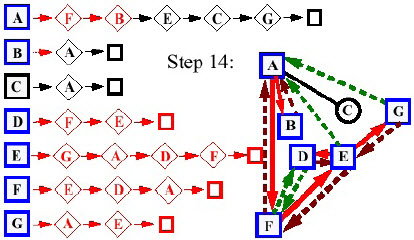
- Bước 15:

- Bước 16:

- Bước 17:

- Bước 18:

- Bước 19:

Ứng dụng
[sửa | sửa mã nguồn]Nhiều giải thuật sử dụng tìm kiếm theo chiều sâu:
- Xác định các thành phần liên thông của đồ thị
- Sắp xếp tô-pô cho đồ thị
- Xác định các thành phần liên thông mạnh của đồ thị có hướng
- Kiểm tra một đồ thị có phải là đồ thị phẳng hay không
Xem thêm
[sửa | sửa mã nguồn]Tìm kiếm theo chiều rộng
Tham khảo
[sửa | sửa mã nguồn]- ^ Dương Anh Đức, Nhập môn Cấu Trúc Dữ Liệu và Giải Thuật, Đại Học Khoa Học Tự Nhiên TP.HCM
- ^ Trương Mỹ Dung, Chương 1. Các khái niệm cơ bản về đồ thị, trang 9, Đại Học Khoa Học Tự Nhiên TP.HCM
Liên kết ngoài
[sửa | sửa mã nguồn]Video demo thuật toán DFS
Từ khóa » Dfs Là Gì
-
Giới Thiệu đầy đủ Về DFS (Hệ Thống Tệp Phân Tán) [MiniTool Wiki]
-
MCSA 2012: Distributed File System (DFS) - Technology Diver
-
Định Nghĩa Distributed File System (DFS) Là Gì?
-
DFS Là Gì? Định Nghĩa Và Giải Thích ý Nghĩa
-
Cây DFS (Depth-First Search Tree) Và ứng Dụng - VNOI
-
Giải Thuật Tìm Kiếm Theo Chiều Sâu (Depth First Search) - VietTuts
-
Hướng Dẫn Cài đặt DFS Step By Step - Nguyen Manh Dung
-
Công Nghệ DFS Là Gì? Những điều Cần Biết Về ... - Intellipure Vietnam
-
[Wireless Router] DFS (Dynamic Frequency Selection) Là Gì Và Nó ...
-
Thuật Toán DFS Là Gì
-
Dịch Vụ Dfs Là Gì - VIETNAMNET.INFO
-
Sự Khác Biệt Giữa BFS Và DFS
-
Cách Thiết Lập DFS Namespaces Trong Windows Server 2016
-
Dfs Là Gì - Nghĩa Của Từ Dfs - Thả Rông
-
BFS Và DFS - How Kteam
-
Tìm Kiếm Theo Chiều Sâu - Wiki Là Gì
-
MCSA 2012: Distributed File System (DFS)
-
DFS Viết Tắt Của Từ Tưởng Tượng Là Gì? - Nhận Xét Wiki
-
Cấu Hình DFS - Quản Trị Hệ Thống Mạng Cho Công Ty Cổ Phần Tasco ...